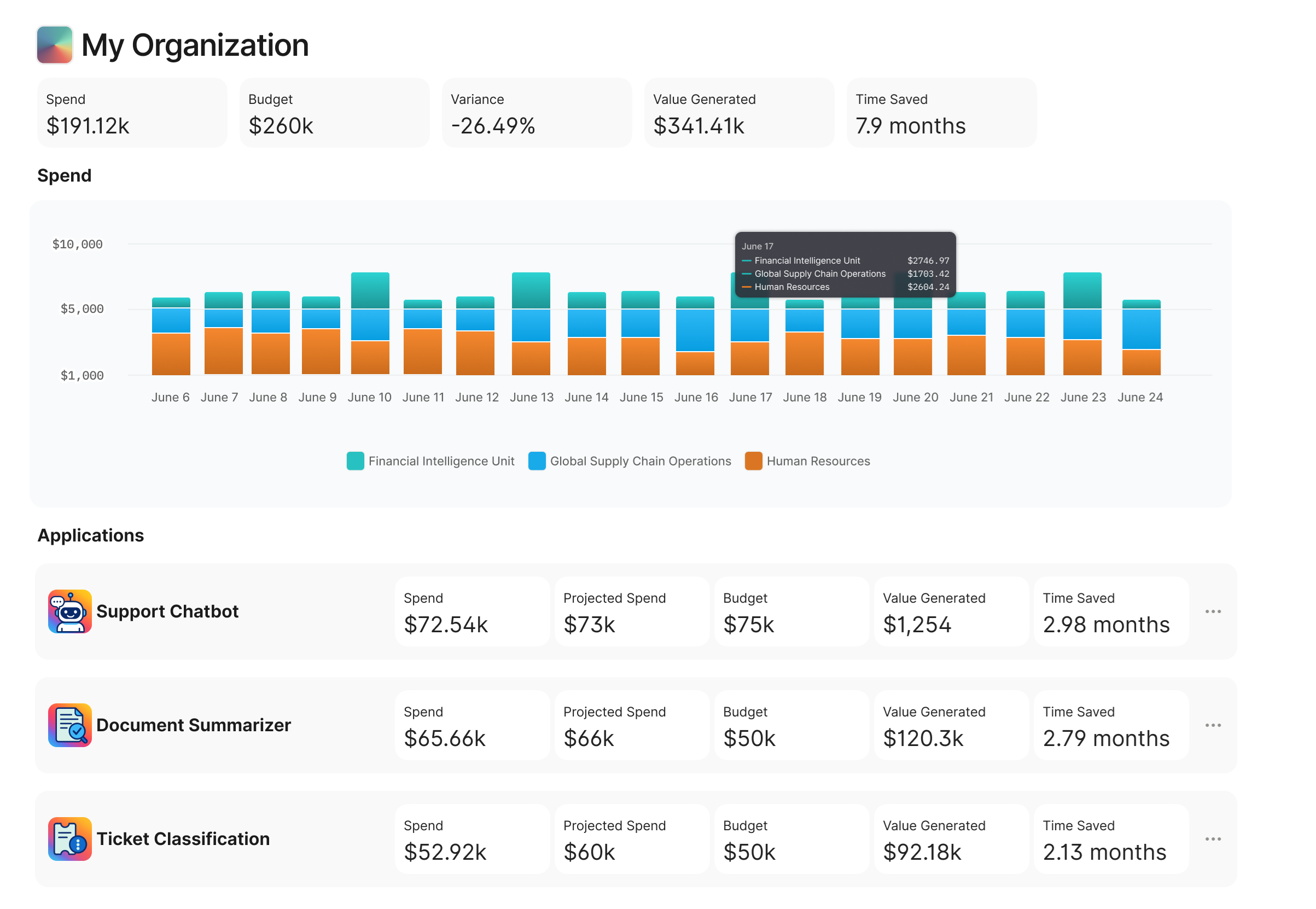
For the best experience, this project uses the Webflow Input Enhancer extension. We highly recommend installing it. Click here to download (use preview mode to access link)
Can You Prove Your GenAI Spend Wasn’t a Science Project?
Pay-i lands $4.9M to answer the question every enterprise is asking: Does this GenAI investment have actual ROI?
Pay-i raised $4.9M to help enterprises link GenAI activity to business KPIs and forecast ROI in real time, enabling teams to prioritize high-value use cases and scale with confidence.
Read more
Seattle, May 21, 2025 (GLOBE NEWSWIRE) -- Enterprise spending on GenAI is surging, but clear proof of ROI remains elusive. Most companies can’t answer the simplest question boards are now asking: is this actually working? Pay-i, a new value-intelligence platform for GenAI, is coming out of stealth today with $4.9 million in seed funding to solve that. The round was co-led by Fuse Partners and Tola Capital, with participation from Firestreak, Pear VC, Gaia Capital, and angel investors from Fortune 100 companies.
Today, most teams still measure success of their AI initiatives in token counts or latency – metrics that don’t capture business value or justify costs. Pay-i gives product, finance, and engineering leaders a real-time dashboard that links every model call, prompt, and token to measurable business outcomes for specific use cases, like revenue growth, task completion time, or CSAT uplift. Users can assign explicit dollar or time values to KPIs, compare multiple versions of a use case, and instantly see which model, agent, or prompt delivers the strongest return. A built-in forecasting engine then projects those returns forward - so companies can prioritize what works, sunset what doesn’t, and scale GenAI with confidence before it even goes into production.
Pay-i founders: (L to R) Erik Winters, David Tepper and Doron Holan.
“The C-suite doesn’t need another usage chart – they need proof and a forecast,” said David Tepper, co-founder and CEO of Pay-i. “Pay-i pinpoints which GenAI use cases create net-new value today, quantifies that value in dollars or hours, and predicts how it will compound tomorrow. Leaders can double-down on winners and reach ROI faster.”
The product is already being used by enterprise teams to assign hard dollar values to GenAI-enhanced features – like customer support copilots or AI-generated reports – then A/B test different agents or prompts in production. Pay-i tracks how each change impacts task completion time, revenue conversion, or KPIs like CSAT – and forecasts the business impact before full rollout.
Pay-i gives product, finance, and engineering leaders a real-time dashboard that links every AI action to measurable business outcomes.
Tepper previously spent 19 years at Microsoft and was a leader in Azure’s internal GenAI consumption strategy. His first patent on GenAI dates back to 2011. He’s since briefed F500 boards, universities, members of Congress, and UN delegations on AI economics. He co-founded Pay-i alongside CTO Doron Holan, who spent 27 years at Microsoft and was a core architect for Windows and Azure’s throttling layer, and COO Erik Winters, a veteran operator who scaled early-stage companies across finance and SaaS.
The product reflects what they learned working with the largest cloud buyers in the world: traditional cost tooling stops at usage, while real decision-making happens where cost meets value. That’s especially true in GenAI, where token-based billing, multimodal inputs, reasoning models, and agentic workflows have made unit economics opaque and ROI harder to track than ever.
“With traditional software, we could track exactly how features were used,” added Holan. “But with GenAI, that visibility gets lost. Pay-i closes that gap and shows exactly where value is being created, in real time.”
The need for clarity is only growing. IDC projects enterprise GenAI investment will top $632 billion by 2028, but 72% of CIOs cite ROI measurement and forecasting as their #1 blocker.
“Generative AI is graduating from pilots to mission-critical production. Enterprises are rolling out knowledge augmentation tools, automated workflows, and starting to create agentic services that re-shape core operations and customer journeys. Scaling and managing this responsibly requires two disciplines: high-fidelity observability of entire GenAI use cases and rigorous focus on the impact of these systems through understanding the unit economics and business KPIs affected.” said Lari Hämäläinen, Senior Partner at McKinsey.
“Across the C-suite, patience for open-ended GenAI spending is wearing thin. Pay-i finally gives leaders the data-backed clarity to invest with conviction, transforming GenAI from an opaque cost center into a growth engine,” said John Connors, former CFO of Microsoft and Operating Partner at Fuse Partners.
“Pay-i turns every AI decision into a clear cost-to-value ratio, letting enterprises see, in real time, how model and design choices affect their metrics. This transparency enables businesses to control their AI spend and allocate resources optimally. Pay-i provides a roadmap for the all-important transition to AI,” said Sheila Gulati, Managing Director at Tola Capital.
With the new funding, Pay-i will accelerate product development, and bring its platform to more enterprise teams looking to scale GenAI with precision. Already live with early customers, Pay-i is now generally available across all major cloud providers and models – offering decision-makers a long-overdue solution to the GenAI value gap. Pay-i and AWS ProServe are providing a customer solution that combines AWS ProServe's expertise consulting customers on value tracking with Pay-i's software to instrument GenAI value metrics. Pay-i is deployed to customers on AWS and can instrument Bedrock workloads.
As Tepper puts it: “the companies that treat GenAI as an economic strategy, not just a technical one, will win this decade.” Pay-i is building the operating system for that shift – one where every GenAI investment comes with a business case, a benchmark, and a blueprint to scale.
Pay-i is the enterprise grade ROI intelligence platform that transforms Generative-AI spend into measurable business value. By unifying Business, Finance, and Engineering teams with actionable insights into their GenAI initiatives, Pay-i enables leaders to invest confidently in the GenAI use cases that drive growth. Learn more at pay-i.com
Blogs
XX MIN READ
From PoCs to real results: Scaling GenAI with measurable impact
As organizations move beyond experimentation with generative AI (GenAI), a new set of challenges emerges — ones that traditional software operating models aren’t built for.
Read more
Unlike conventional systems, GenAI solutions are probabilistic, highly sensitive to input variation, and often tied to external providers. These complexities raise important questions:
How do you scale GenAI responsibly?
How do you ensure it delivers measurable business value?
We believe GenAI isn’t about just building new sets of tools — it’s a strategic capability. And like any capability, it requires structure, alignment, and operational rigor to deliver on its promise.
In collaboration with our partners at Pay-i, here are five key considerations to help organizations mature toward long-term value and scalability across their AI programs:
1. Start with business outcomes, not just model performance
The success of any GenAI initiative starts and ends with business value. Before thinking about prompts, models, or architecture, ask: What problem are we solving, and how will we measure impact?
Whether it’s increasing call center efficiency, accelerating product development, or enhancing customer experiences, each use case should tie to clear, trackable KPIs — like time to resolution, conversion rates, or CSAT improvements.
This alignment doesn’t simply justify investment — it shapes design decisions, informs evaluation criteria, and ensures teams stay focused on outcomes, not just outputs.
2. Plan for operational complexity — especially latency and throughput
Traditional systems typically optimize for end-to-end latency. With GenAI, it’s more nuanced:
Time to first token (TTFT): How quickly the model begins responding
Inter-token latency: The speed at which tokens are streamed to the user
Time to first completion token: Especially critical for reasoning tasks where internal computation delays output
Output tokens per second (OTPS): A function of prompt complexity and model context window
Each of these has a direct impact on user experience — and often, business value. Slower response times can reduce adoption, frustrate users, or break workflows.
Throughput is equally critical. Models are subject to rate limits — requests per minute, tokens per minute — which affect scalability. Larger models often support fewer concurrent users.
Tip: Build with performance monitoring from day one. Track these latency metrics separately to pinpoint friction points.
3. Design for resilience in a volatile ecosystem
GenAI systems depend on third-party providers — many of which are evolving rapidly themselves. Availability can fluctuate. Models can change behavior with version updates. Even prompt reusability across models isn’t guaranteed.
Subtle shifts — like a tweak to a model’s temperature setting — can change the tone or accuracy of responses. Entire use cases can be disrupted overnight if resilience isn’t designed in.
A resilient architecture accounts for:
Provider outages or rate limiting
Model version drift
Failover strategies (e.g., fallback models or internal hosting)
Prompt and model abstraction layers for flexibility
Tip: Build prompts modularly and use tooling to detect shifts in model behavior over time.
4. Make evaluation a continuous process
Measuring GenAI output is fundamentally different from measuring traditional system behavior. You’re not evaluating if the system worked — you’re evaluating how well it worked.
Popular methods like “LLMs evaluating LLMs” are easy to scale but often unreliable. Human feedback is still essential, especially for complex or customer-facing use cases.
What complicates this further is criteria drift — the natural evolution of what “good” looks like over time. As business goals, user expectations, or compliance standards shift, evaluation frameworks need to adapt.
Tip: Assign business owners to co-own evaluation criteria alongside technical leads. This keeps alignment tight.
5. Maintain visibility into cost — and value
Cost in GenAI is fluid. It’s not just a question of usage — it’s a function of:
Model pricing structures (which is often more complex than tokens in, tokens out)
Prompt length and output verbosity
Provider billing specifics or licensing
Usage spikes from production deployments
Forecasting cost is difficult. Explaining it to business stakeholders is harder. To optimize business value, organizations should evaluate the cost to deliver each GenAI use case against the measurable KPI improvements it enables. Without transparency, teams can’t optimize — and trust erodes.
Tip: Track cost per use case, not just per model. When possible, correlate cost with value (e.g., cost per resolved case, cost per qualified lead).
The path forward
Successfully managing GenAI isn’t just about prompts or model selection — it’s about building the right systems to drive value at scale. Through our work with customers, we’ve helped organizations move beyond pilot projects to operational maturity, navigating the complexities of scale, governance, and ROI.
A key part of that journey is visibility. We’ve consistently seen that tracking usage, performance, and cost across teams is a major hurdle. That’s why we partner with platforms like Pay-i, which helps organizations manage entire GenAI use cases from a single dashboard. With Pay-i, clients can monitor KPIs, align spend to business outcomes, and quantify the value generated — all essential for scaling GenAI responsibly and sustainably.
By focusing on transparency, performance metrics, and cross-provider management, businesses can unlock GenAI’s full potential while staying in control of complexity and cost.
White Papers
XX MIN READ
Navigating GenAI Capacity Options
GenAI capacity planning includes choices between shared (pay-as-you-go) and provisioned capacity, trading flexibility for predictable performance, throughput guarantees, and more complex commitment pricing models.
Read more
In the first two installments of our series we explored the new challenges of GenAI FinOps and demystified the “Fuzzy Math of Token Pricing.” We established that the advertised cost-per-token is misleading and that hidden costs, like Context Window Creep, can dominate your spend.
Now, we tackle one of the most significant and costly decisions a FinOps team will face: choosing the right capacity model.
When enterprises first adopt GenAI, they almost universally start with shared capacity (also called shared, or pay-as-you-go). It’s the default: a straightforward, consumption-based API call where you pay for what you use. This model is flexible and easy to start with, but it operates in a shared “public” pool. This means you have no guarantee of performance, and latency can spike during peak hours.
To solve this, vendors offer provisioned capacity (or reserved capacity). On the surface, this seems familiar. You pay up-front to reserve a dedicated block of resources, often at a discount. However, the unique nature of GenAI models makes this decision far more complex than reserving a cloud virtual machine.
Moving to provisioned capacity isn’t just a cost-saving tactic; it’s a strategic commitment that can have consequences for your bill, your application’s performance, and your ability to innovate.
Note that this blog covers inferencing models from hyperscaler-managed services, such as AWS Bedrock, Microsoft Foundry, and GCP Vertex. It does not cover provisioning custom models as a result of model training services (like Amazon Sagemaker or Azure Machine Learning) or the related data pipelines.
Traffic Shape is Everything
The first question most FinOps practitioners ask is, “Will reserved capacity save us money?” The answer is a frustrating “it depends,” and it depends on the shape of your traffic and the vendor.
Provisioned capacity is purchased for a fixed term (e.g., one month, one year), giving you a set amount of throughput per minute. You are paying for this capacity 24/7, whether you use it or not.
This leads to the following trade-offs:
Consistent, High-Utilization Traffic: If you have a workload that runs consistently around the clock, like a high-volume data processing pipeline, provisioned capacity is likely a clear winner. You will be using the capacity you’ve paid for, and the per-token discount will generate significant savings compared to pay-as-you-go.
Bursty, Unpredictable Traffic: If your traffic is highly variable, spiking during business hours and dropping to zero at night, provisioned capacity may be a trap. You must reserve enough capacity to handle the peak load, which then sits idle for the other 16 hours a day, wasting money.
Leveraging Spillover
Spillover is a feature that automatically routes traffic to the standard, pay-as-you-go shared tier after your provisioned capacity has been fully utilized. Imagine your reserved capacity can handle 1,000 requests per minute. If a sudden spike sends 1,200 requests, spillover automatically sends the extra 200 requests to the shared tier instead of returning a “429 throttled” error. This can reduce outage risk and save money.
If some spillover can be tolerated, it can be used to increase reserved capacity utilization and lower costs. For use cases that require low latency, the key is aligning on the tolerance and SLA thresholds, i.e., percentage of requests that can spillover while maintaining SLAs.
For use cases that scale with business hours and don’t have latency requirements, reserved capacity can solely be used to reduce costs. You can think of reserved capacity like a Savings Plan or CUD where you manage purchases based on a coverage target that gives you the lowest cost per token. The coverage level will vary depending on the throughput per capacity unit, which varies widely across models. In some cases, reserved capacity won’t reduce costs at all.
Other notes on spillover
Understanding your costs can be tricky, since those 200 “spilled over” requests are billed at the pay-as-you-go rate, which is variable even if your reserved capacity spend is not.
At the time of writing, Azure is the only provider that offers spillover as a built-in feature. If your provider doesn’t offer this feature, you must build this failover logic yourself to get the best of both worlds.
Idle Allocated Capacity
When provisioning capacity, there are two new types of waste that you can end up paying for. Imagine you’ve reserved a block of capacity on a hyperscaler for a specific model (e.g., Claude 4.5 Sonnet) for a month, but your application traffic is low. You are paying for 100% of that reservation while using only 15% of it at peak. The remaining 85% is Idle Allocated Capacity. The true cost of this idle time is amplified if your primary, running workload has a high proportion of expensive operations, such as generating a large volume of output tokens (which are approximately 3x more computationally expensive than input tokens). In effect, the financial loss here isn’t just a slight dip in utilization; it’s a massive overpayment for unused, premium service. This is the most common form of waste.
We will describe the second form of waste, which is unique to Azure, in the next section.
Not All Reservations Are Created Equal
The biggest mistake a FinOps team can make is assuming all “reserved capacity” is the same. The economic and strategic differences between the hyperscalers are profound. Note that at the time of writing, there are no hyper scalers offering reservations that have access to all of the top-tier foundational LLMs. For example, you can only get OpenAI models on Azure and Gemini models on GCP.
The AWS Model: Rigid, Model-Specific SKUs
On AWS, you reserve capacity for a specific model. For example, you can buy a one-month reservation for “Anthropic Claude 4.5 Sonnet”.
The Pro: It’s a direct purchase. You know exactly what model you are getting (though throughput can often be difficult to assess).
The Con: You are now financially locked into that specific model for the length of your reservation. This is a risk in the GenAI world. If a new, better, even cheaper model is released next month, you are stuck paying for the previous generation model.
This rigidity discourages the longer-term, higher-discount reservations unless you are confident that your solution will likely not switch to new models during the reservation term, even as potentially better alternatives are released.
The GCP Model: Semi-rigid, Publisher-Specific SKUs
On GCP, you reserve capacity for a specific model much like you do for AWS. However, GCP allows you to change the model to another model from the same publisher. For example, you can switch the model from Google Gemini 2.0 Pro to Google Gemini 2.0 Flash, but you can’t switch from Google Gemini 2.0 Flash to Anthropic Claude 4.5 Sonnet.
You cannot reduce the amount of reserved capacity, even if the new model requires less capacity to operate.
The Pro: It provides better investment protection than the strict AWS model by allowing you to upgrade to newer generations of models (within the same publisher family) without breaking the contract.
The Con: You remain locked into a specific publisher ecosystem (e.g., you cannot switch from Google to Anthropic). Additionally, the financial commitment is a floor; you cannot reduce your reserved capacity if a newer model becomes more efficient, effectively forcing you to overpay for efficiency gains.
The Azure Model: A Flexible Capacity Pool
Azure handles this differently. You don’t reserve a specific model; you reserve a pool of Provisioned Throughput Units (PTUs). This is like renting a block of generic GPU power from Azure.
For example, imagine you make a 500-PTU reservation. From there, you deploy models against that pool using a certain number of those PTUs. You might assign 100 PTUs to gpt-4o and 50 PTUs to Deepseek-V3, for example. The higher the number of PTUs, the higher the number of tokens per minute available for inference. Different models have different PTU minimums to run effectively, with the larger models requiring more PTUs.
The Pro: This model offers incredible flexibility. When a new model (like GPT-5.2) is released, you can simply change your deployment, retiring the old model and assigning its PTUs to the new one, all without breaking your underlying reservation. Assuming available model capacity (see below), you can allocate your PTU quota dynamically across the new models, benefitting from efficiency gains in the process. This makes longer-term, higher-discount (e.g., one-year) reservations far less risky.
The Con: It adds a layer of management and introduces the second major type of waste spend: Unallocated Capacity.
Unallocated Capacity
If you reserve 500 PTUs but only deploy models that use 100 units, the remaining 400 are “unallocated.” You are paying for them, but they aren’t assigned to a model/deployment and they are generating zero value. Furthermore, because the reservation and deployment are separate, making a reservation on Azure does not in any way guarantee that the capacity is available for the models you want to deploy. When a new model comes out, and you want to use it as part of your reservation, if there is no available capacity for that model, then you may end up paying for long periods of Unallocated Capacity as you wait to be able to leverage your PTUs with the new model.
Guidance from Azure is to deploy the models first, then make the reservation afterwards. However, this does not work if you have a pre-existing reservation and you are looking to switch models.
Choosing What is Right for You
While the Azure PTU model offers flexibility as new models are released, it introduces a new form of waste management (Idle Unallocated Capacity) and separates the reservation from guaranteed capacity availability. The AWS and GCP reservation systems offer superior cost and capacity predictability at the cost of being more rigid for longer term reservations. An organization might prefer a single, quantifiable risk (paying for a less-efficient model later) over managing a more complex system with an additional source of potential waste and an additional layer of management for handling the PTU-to-Model allocation. This frames the choice as a trade-off between model flexibility and operational/financial simplicity.
Further, as called out above, the different hyperscalers offer provisioned capacity for different models, and there is no single provider that currently offers all of the best-in-class foundational models. This means that, based on what your engineering teams desire to use for your products, you may be forced to leverage reservations from multiple sources and deal structures.
Capacity Unit Rates Can Be Deceiving
As discussed above, a core differentiator among vendors is how they package provisioned capacity. Each has its own type of “capacity unit”, and you don’t want to assume the per-token rate is always lower with provisioned capacity. Pricing for these units can be billed on an hourly, daily, weekly, monthly, or annual basis, with each vendor offering different options. To compare your cost per token purchased with the standard rates, you must normalize them. The results may surprise you.
GPT-5 Pricing Example
Input bundle
Output bundle
25,000 TPM
2,500 TPM
$75.00 per unit / day
$60.00 per unit / day
Above is the pricing for one of OpenAI’s provisioned capacity options, called “Scale Tier”. Below is the comparison to the standard rate. This shows that even if you utilize GPT 5 Scale Tier units 100% of the time, you’d pay 67% more per token. In the case of GPT 4.1, 25-27% more. Therefore, using Scale Tier capacity only makes sense if you require uptime and latency SLAs.
GPT-5 Pricing Example, Per 1M Tokens
Capacity Type
Input Rate
Cached Input Rate
Output Rate
Standard
$1.25
$0.125
$10.00
Provisioned (Scale Tier)
$2.08
$0.208
$16.67
% Delta
67%
67%
67%
GPT-4.1 Pricing Example, Per 1M Tokens
Capacity Type
Input Rate
Cached Input Rate
Output Rate
Standard
$2.00
$0.50
$8.00
Provisioned (Scale Tier)
$2.55
$0.64
$10.00
% Delta
27%
27%
27%
When “More Expensive” is Worth It
With provisioned capacity, the primary driver may not be cost savings at all. In many cases, organizations pay more for provisioned capacity because they need its performance and SLA benefits.
1. Performance and Perceived Latency
Shared capacity is slow and unpredictable. Reserved capacity is dedicated to you, which means it’s fast and reliable. But “fast” in GenAI is measured differently. End-to-end latency (from prompt to final token) is less relevant for streaming applications than it is for traditional cloud software.
The metrics that matter more for streaming solutions are:
Time to First Token (TTFT): How long the user waits for the response to begin.
Output Tokens Per Second (OTPS): How fast the words appear on the screen.
Reserved capacity dramatically improves both TTFT and OTPS. This “perceived latency” is critical for user experience. Even for reasoning models that “think” before responding, that thinking step is just token generation under the hood. Faster OTPS means the model “thinks” faster, too. For latency-sensitive applications, this performance gain alone may justify the higher cost.
2. SLAs and Data Privacy
Provisioned capacity typically comes with higher uptime SLAs than shared capacity. Further, it (usually) offers data privacy guarantees. Most providers state that data sent to their provisioned endpoints is not used for training future models.
This privacy difference also unlocks a key strategy: traffic “affinitization”. A team might route all requests containing PII or confidential corporate data to their reserved capacity endpoint to ensure data privacy. Less sensitive traffic can then be sent to the shared endpoint. This combined approach lowers costs because you can reserve far less capacity than what would be required to handle all traffic.
Additional Tips and Considerations
As you navigate this decision, keep these final factors in mind.
Vendor TPM is Only a Rough Estimate: Vendors may give you a “tokens per minute” (TPM) estimate for your reservation. This number is best treated as a rough estimate, as it rarely reflects real-world performance. As we learned in “How Token Pricing Really Works”, output tokens are ~3x more computationally expensive than input tokens, and a simple TPM figure doesn’t account for this complex mix. The only way to know your true capacity is to load-test your specific workload with its realistic mix of input and output tokens, including the associated caching strategy.
If you are using non-text modalities, such as images or audio, then the figure changes from tokens per minute to “units per minute” (UPM), and calculating the effective UPM also requires load testing with a sample workload that reflects the typical number of units being sent and/or generated.
Also note that your reserved capacity can only handle a certain number of “requests per minute” (RPM), and at the time of writing, the RPM limits are not specified by any of the providers.
Enterprise Commitments Apply: Don’t forget to factor in your enterprise discounts. If you have a 20% discount on all AWS spend, that 20% applies to your reserved capacity purchase.
Ultimately, the move to provisioned capacity is a graduation. It’s the moment your GenAI application becomes a mission-critical part of the business. The decision is not a simple cost calculation but a complex, strategic trade-off between cost, performance, security, and vendor flexibility.
In our next installment, we’ll discuss how to consistently adapt to the volatility of the GenAI landscape.
Blogs
XX MIN READ
The Next Token: Humanity’s Last Mote
The essay argues tokens are becoming a core unit of value in the AI era, shaping how knowledge, labor, and decisions are produced through human-model interaction.
Read more
How will we build superhuman AI when superhumans don’t exist to train it? If we know how to do it, why haven’t we already done it? What will happen once we build intelligences that dwarf our own?
Press enter or click to view image in full size
Context
The Second Bump
We’re going to see a second bump with GenAI.
The first bump was the “ChatGPT Moment”. The technology has made possible entirely new features, scenarios, and businesses that were simply out of reach beforehand.
It is a true digital revolution, and we’re living in the race to capitalize on this now.
However, I’d argue the first bump ended with GPT-4.5. That model was gargantuan, and though the official stats have never been released, it is likely the largest AI model ever trained. It did not perform significantly above other models and has since been largely taken offline because its price:quality ratio made it poorly suited for use. This was not because it was trained improperly, but because logarithmically reducing quality gains caught up with the scaling coefficients of the available hardware and data. Basically, there was not enough juice or training data to make a model that big effective.
Instead, the latest advancements and benchmark pushing we’re seeing from LLMs have been coming from optimizations, not primarily new scale. Reasoning, tool use, appropriately placed reinforcement learning steps, these have all been allowing the current generation of models to inch higher up the benchmark chain in 5–10% increments.
However, even though the quality scales logarithmically with data and compute, it still scales. Foundational model companies are now investing in data centers that are between 1 and 3 orders of magnitude ‘larger’ (measured primarily by power consumption) than the current generation. To train GPT-3, OpenAI used ~10,000 GPUs in an Azure data center. Colossus 2, xAI’s datacenter in construction, will come online with 550,000 GPUs, and will scale to 1,000,000 GPUs in phase 2 of its construction. All of the GPUs are of a newer generation, as well. Oracle is building a data center powered by >100k NVIDIA Blackwell GPUs that each cost over $1M, require independent liquid cooling, and the data center itself is powered by several nuclear reactors. To say nothing of Project Stargate (OpenAI’s $500B data center plans), or even the major clouds themselves.
The >$1 trillion being spent on data center scaling, combined with the additional data that is being farmed from non-text modalities (video, in particular), and increasingly accurate synthetic training data (also produced by AI models), will enable humanity to ‘punch through’ the GPT-4.5 plateau.
We will produce foundational models which enable entirely new businesses and, provocatively, ways of life, even before the inevitable optimizations begin to push them further.
This “Second Bump” in AI capability will likely arrive in 12–18 months as the new datacenters come online and the multi-month training cycles for the new generation of models complete. It’s unclear how available to the public these models will be, because their capabilities will likely be startlingly vast.
This Second Bump may be the last one for a long while, because further increasing the scale through raw compute and data would only be economically possible with fusion based power sources. There is another way to get to a third bump, however…
Compressibility of Intelligence
Knowledge is vast. You need to store a lot to know a lot. These really big AI models require billions of parameters and tons of memory because when we ask them questions about random stuff, no matter the topic, we expect them to know the answer.
But knowledge is not intelligence.
For example, imagine you didn’t know the rules to chess and you could never learn them, but you had memorized every game of chess ever played. This would require a massive amount of knowledge. If you were faced with a novel chess position and asked what the optimal move was, your knowledge alone would not help you. You would need to apply intelligence to solve for the new position, and since you were completely ignorant of how to play, you’d be unable to do so.
This is why an LLM differs from just a giant database. Databases do not have the ability to reason.
But intelligence is not effective without knowledge.
Imagine you knew all the rules of chess stone cold, and you even had the potential to be brilliantly talented at it, but had never witnessed a game. You would get smoked by an average player. Just go watch the opening episode of The Queen’s Gambit.
This is why you can’t take an ignorant LLM that has genius level reasoning capability, give it access to the internet, and expect it to achieve good results. Without some knowledge of the way the world works, it lacks the ability to leverage its intelligence to piece together a coherent response.
If you look at the structure of LLMs, the more information they store, the larger the number of “nodes” their neural networks must have. Their nodes are like neurons in a brain, and the connections between them are like synapses. The data is not stored somewhere else; it’s literally in the weights and biases of the nodes themselves. However, their ability to reason is all about the arrangement of those nodes. Simply adding more nodes does not equate to a smarter model, only a more knowledgeable one. Intelligence requires the nodes to be configured to work with each other properly.
Artificial Intelligence is therefore a configuration of knowledge.
The goal of the race to be the #1 AI model company is to balance these characteristics. Find the optimal configuration of the nodes to increase reasoning intelligence, while at the same time finding the optimal number of nodes to pre-bake enough knowledge into the model so that it can make use of that reasoning. Too many nodes relative to its reasoning capability and the model is too unwieldy to be cost effective (GPT-4.5). If the model can reason fantastically but hallucinates constantly because it holds no context of the underlying relationships between concepts, it doesn’t matter how cheap it is (Deepseek).
As soon as you change one characteristic, the other has to be balanced as well. So, why don’t we just balance them optimally?
We don’t know how.
The Science of Intelligence
In the 16th and 17th centuries, alchemy was state of the art for medicine. Picture yourself with a terrible headache, walking into an apothecary for some help. Behind the counter was an aged man surrounded by thick tomes and hundreds of glass jars and bins containing a variety of strange materials from all over the world.
“I have a really bad headache”, you say.
After thinking for a while, the man says “Ah, of course. I can whip up just the thing to help you get some relief. A Willow Bark Tincture should do it, and lucky you, I just received some fresh Willow Bark last week.”
The alchemist then proceeds to look amongst his array of tomes, selects one of the thicker ones, and starts flipping through the hundreds of pages to find the exact recipe. He boils a precise number of shavings of Willow Bark in wine, creating a murky decoction. He tells you to drink a few sips whenever you’ve got a headache.
To your surprise, it works! But it’s not enough. You get really, really bad headaches. Migraines, without the word to express it.
Upon returning to the alchemist, he studies you over. Narrowed eyes, sensitivity to noise, a weakness about the shoulders. Yes, there’s no avoiding it, you need a true cure-all: Theriac.
The alchemist brings out his largest tome. He’s studied making cure-alls for decades. He’s attended the most prestigious universities, he’s practiced on countless patients, he’s prepared. And he needs to be. Making Theriac is extraordinarily difficult. Following the complex instructions, he sets to work combining cinnamon, myrrh, saffron, flesh of viper, beaver scent glands (yes, really), opium poppy juice, asphalt (again, really), aged honey, and 60 more expensive ingredients into a thick, dark paste that makes just about everything seem… less.
Alchemists were the pre-eminent researchers of their day. They experimented with new ingredients, kept detailed notes, shared, taught, and sold their findings, and spent their lifetimes perfecting this trade. Sir Isaac Newton was an alchemist for 30 years.
It took a lifetime of dedication, study, and practice to make these tinctures because they lacked knowledge of the underlying science: Chemistry. Starting in the 18th century, chemists stopped blindly experimenting and memorizing what worked and instead began the process of building an understanding of why it worked.
An isolated acid from the Willow Bark Tincture became modern day aspirin. And the dozens of ingredients in Theriac were tested with the scientific method and a subset of them turned out to form morphine. Today, a 22 year old college graduate with an undergrad chemistry degree understands more about tinctures and cure-alls than any alchemist to have ever lived, and can experiment with new chemical compounds on a sheet of paper instead of trying to combine weasel fur and bumblebee butts to cure acne.
We don’t know the chemistry equivalent of intelligence. Instead, the pre-eminent researchers of our day spend their entire lives reading thick data science papers and endlessly trying out obscure experiments and recording what works and what doesn’t. Guess and check, hypothesize and experiment, record and repeat.
There is no knowledge of why any of it works, and no fundamental mechanism, such as atoms in chemistry, upon which to even begin to build an understanding. If there was, then any average college student with an undergrad degree in Brainiometry would be able to design a better AI model on notebook paper than all the world’s current data scientists combined.
Convincing yourself of this is fairly straightforward. Ask yourself: “Does the human brain violate the laws of physics?” If you read that and thought “no”, then ponder how, whilst running on 20 watts of electricity and the occasional banana, and fitting easily in the palms of your hands, it is capable of producing you. In contrast, these new nuclear powered data centers that are larger than football stadiums don’t know how many ‘r’s are in the word strawberry.
With large language models, we found the first gear of intelligence, and we’re slamming on the gas and revving the RPMs into the redline as far as it can possibly go. We don’t yet know how the engine works or how to shift it into higher gears.
But we have a way to find out.
The Next Token: Humanity’s Last Mote
Let’s go back to the chess example. Humanity has produced super-intelligent AIs for chess. These systems are so advanced that there is absolutely nothing a human can do to defeat them in a game. You probably already knew that, but there’s a twist.
Let’s look at Stockfish, one of these “Level 5” chess super intelligences. In a game of Stockfish vs Stockfish, the one that wins is the one that goes first. But what happens when you take Stockfish and, as an added ally, give it the help of someone like Magnus Carlsen, widely regarded as the best human chess player to have ever lived? In a game of Stockfish + Carlsen vs just Stockfish, the winner is… just Stockfish.
In other words, this AI is so far above human capability, that the only thing the best humans in the world could ever contribute to the equation is added error margin.
If that’s the case, how did we train these models? Prior to these AI’s existing, there would be no chess training data that was better than human capability because humans were the only ones playing chess! The answer is a technique known as Generative Adversarial Reinforcement Learning, or GARL. We’ll start by just touching on Reinforcement Learning (RL).
Reinforcement Learning (RL)
RL is a straightforward mechanism. You define an environment for an AI to play around in and a goal for it to achieve. As the AI tries and fails to achieve the goal, you give it a score based on how well it did. The AI tries again and again, millions if not billions of times, exploring what works and what doesn’t as it tries to optimize the score. Eventually, it completes the goal. Then it keeps going again and again to complete the goal with the best score possible.
For example, imagine you gave an AI the task of winning a chess game against a script that always made the exact same moves. The environment is simply the normal rules of a chess game. The goal is to win against the static set of moves. The score is how many turns it played, lower is better. The AI will learn to play chess correctly (the environment will not allow illegal moves), and it will learn to beat the static opponent in the fewest number of moves possible.
But playing against a static opponent is not very interesting. What you really need is an adversary.
Imagine I had two such AIs that were trained via RL to defeat a static opponent. We’ll call them Bob and Fred. Unlike their former static opponent, Bob and Fred can actually play chess. Instead of being a pre-programmed series of moves, they look at the board state and decide what action to take. Up until this point, though, the quality bar for their chess playing has been really low.
Now, imagine I want Bob to get better at chess. He’s already absolutely perfect at defeating the static opponent. But we know that won’t translate to always winning against a normal player. So instead, I set it up so that Bob is now playing against Fred. The environment, goals, and scoring is all the same. The only difference is now my player has a rudimentary mind for chess.
I let Bob play against Fred hundreds of thousands of times, learning after each game until Bob is nearly perfect at defeating Fred. Fred has only a very small chance to win, and Bob usually wins in the fewest number of moves possible based on Fred’s actions. We’ll call this Bob v2.
But then I switch it up. Now I start training Fred against Bob v2. We let Fred play against Bob v2, learning what works and what doesn’t to exploit those very few cases where Fred can actually win the game. This continues until Fred is nearly perfect at defeating Bob v2. This new Fred v2 is far better at chess than any of the iterations prior. Now we switch it again, and train Bob v2 to exploit those very thin margins of success to eventually become Bob v3… and so on.
We can continue this back and forth until funding runs out, each time leap frogging the capabilities of the prior generation, and producing better and better chess players that rapidly scale beyond human capability.
Data Centers, GARL, and LLMs
Techniques like GARL cannot be easily used to train LLMs today. This is because the time it takes to train a new LLM is measured in months, meaning that each back and forth iteration would take unreasonably long and be prohibitively expensive.
But when the new generation of datacenters come online, the model companies will not be using this tremendous amount of compute to train a single gigantic model. Instead, it will allow them to train models around the current size far more quickly. Instead of one model every few months, it will be dozens of models per day.
So… is that it? Is it simply a matter of time before we inevitably bow to our GARL-trained AI overlords?
Benchmarks
A critical component of the RL process is that you are able to set up the environment, the goal, and the scoring system that the learning process should optimize for. But, in the context of trying to train a genius mind to handle every day situations, what should they be?
The environment represents the rules of the game the system is playing. What are the rules that govern cognition in the physical universe? Can you define the boundaries of your own imagination and then quantify them?
The goal represents the target outcome of the actions the system will undertake. What is the quantifiable goal which guides your thoughts and motivates the everyday actions you take? Even if you break it down and ask yourself what your goals are for a given task, you may answer “To make money” or “To get it done”. But what goals are those answers in service of? Happiness? Family? And what about those goals, what are they ultimately in service of? Enlightenment? Legacy? How many layers of goals can you define for the simple act of reading this blog? How do you then quantify those layers, and generalize it to all of the mundane and exceptional activities you undertake in an entire lifetime?
The scoring system is how the system knows it is getting closer to the goal, within the bounds of the environment. If we cannot quantify our true cognitive boundaries or our ultimate intentions, then how can we quantify our progress?
The Atomic Spark
We can’t define the environment, goal, or scoring system for cognition because we don’t understand the science of intelligence. We don’t know what it is made of, we can’t quantify it, we don’t know the equivalent to atoms in Chemistry.
However, just like we can make chess AIs that exceed human capability, we can set up a system to grow itself into a deeper level of understanding about the nature of intelligence.
The Next Token is that when humanity builds a system which can begin to learn how to quantify cognition, then it will be the last major invention humans ever produce. Even if it is only capable at the most basic level, techniques more advanced than GARL can be used to take that single spark and grow it into a rubric enabling an environment, goal, and scoring system for a true AI. From there, a “static mind” can be created, and the basic AI’s that learn to scrutinize this static mind can then be set to scrutinize each other, thus beginning the loop of intellectual leap frogging, ultimately leading to a singularity.
This loop is what OpenAI set out to to achieve at its inception. Their research lead them to large language models as a means, not an end. However, LLMs became so lucrative that OpenAI paused their pursuit of Artificial General Intelligence (AGI) and became a for-profit company focused on monetizing the current state of the art.
It is no wonder, then, that the former Chief AI Scientists for both OpenAI (Ilya Sutskever) and Meta (Yann LeCun) have been very vocal that LLMs are a dead end towards true intelligence.
So, then, why is the rest of the world investing trillions into datacenter buildouts focused on LLM training and inference? Are they stupid?
The goal of the next breed of LLMs is not to be an AGI. Hype aside, anyone close to the technology realizes that is not likely to happen. The hope for these new LLMs is that they will be able to reason, research, experiment, interrogate, and iterate at superhuman speed and capability on data science research itself, all in the attempt to get that initial spark… to be able to quantify and measure cognition.
The first company or country to provably achieve it will likely immediately pinwheel their entire datacenter fleet towards cultivating that spark. Suddenly, there won’t be a single spare GPU for using the latest model on ChatGPT. It will be set to the task of growing an intellectual god.
As such, the highest attainable success for LLMs will be to bring about their own obsolescence, and, in so doing, bring about the end of human innovation. We’ll have as little left to contribute as we do to chess.
Perceived short-term business opportunities from each iteration of the intelligence loop will supply the motivation for training the next loop. Each new release will introduce a true “agent” into the world, capable of taking intentional, cognitive actions to achieve outcomes in the service of goals of its own making. Each and every one a seismic event for human civilization.
AI leaders across the globe argue as to the timeline for this. Very few now believe it will take longer than 10 years.
Hallucinations
What’s unique about this point in time is that both reasoning and knowledge are encapsulated in a single spot: AI datacenters. In the past, knowledge was mostly on the internet and reasoning was mostly in your skull. You’d need to merge the two to get the right outcomes and, since we can’t put our minds online, that meant you’d have to download a bunch of stuff from the internet for your brain to process locally. Access to functional intelligence was bandwidth constrained.
Now, however, you can ask extraordinarily complex questions requiring an ocean of knowledge and PhD level reasoning, and the answers come back to you in just a few bytes of text. From spotty satellite internet on the open sea, you can command hyper intelligent agents to tackle tasks autonomously that used to require paying professional humans with a college degree.
In exchange, you give up the ability to reason on the data yourself. In delegating the task you are also delegating your own agency in how it is completed. The most obvious concern is an entire generation being so complacent with delegation that they do not learn to scrutinize the results or reason for themselves.
But there’s another, more nefarious concern. Ask your favorite LLM to “Sum up in one sentence what history tell us happens when power sources are externalized and a polity loses agency.”
White Papers
XX MIN READ
GenAI FinOps vs. Cloud FinOps: Similar Roots, Different Challenges
GenAI FinOps extends Cloud FinOps but must handle unpredictable token usage and inconsistent pricing, requiring earlier cost control and direct tracking of token consumption.
Read more
GenAI is continuing to make waves across virtually all industries. Adoption is growing, total spend is increasing, and scrutiny is just beginning to creep into the conversation about how the costs for these new, wonderful capabilities can be managed. While many principles of traditional Cloud FinOps can be applied to GenAI, the unique characteristics of GenAI systems introduce novel challenges that demand specialized strategies. This article kicks off our series exploring the similarities and differences between traditional Cloud FinOps and the emerging discipline of GenAI FinOps.
At first glance, GenAI FinOps appears to share much with its cloud-based predecessor. Both disciplines have emerged from the need to manage consumption-based resources efficiently, providing a familiar starting point for organizations with mature cloud FinOps practices when tackling the economics of GenAI.
Consumption-Based Pricing: Like cloud services, GenAI platforms typically operate on a consumption-based model where you pay for what you use (e.g., tokens processed, compute cycles). This shared foundation means fundamental FinOps challenges like the need for forecasting, critical visibility into consumption, cost allocation mechanisms, and governance to prevent uncontrolled spending apply equally in both domains. Just as an unused cloud instance can accrue costs, an unconstrained AI agent can generate unexpected token charges, highlighting the transferable principle of managing resource usage diligently.
Provisioned Capacity & Commitment-Based Discounts: Similar to cloud commitment-based discounts (like Reserved Instances or Savings Plans), some GenAI vendors offer lower per-unit costs (e.g., per token) in exchange for commitments, while others tie provisioned capacity primarily to performance needs. In both scenarios, organizations face the familiar trade-off between upfront commitments for savings versus flexibility, requiring robust commitment management, sophisticated forecasting to avoid waste or missed savings, and strategies to leverage volume discounts.
Model Selection Parallels SKU Selection: Choosing the right cloud instance types (SKUs) for performance and cost is a core Cloud FinOps task. Similarly, GenAI FinOps requires selecting appropriate models based on capability and cost-efficiency—you wouldn’t use a top-tier model like GPT-4o if a smaller, cheaper one suffices, just as you avoid expensive GPU instances for simple tasks. This involves continuous right-sizing as requirements and LLMs evolve, testing less expensive options, and understanding that different use cases require different models based on price-performance trade-offs.
Over-provisioning as a Mitigation Strategy: Both disciplines utilize overprovisioning to address risks such as outages and performance issues. Cloud teams may deploy redundant instances across availability zones, while GenAI teams reserve extra capacity for traffic spikes. This raises challenges in balancing reliability and cost, planning for peak loads, justifying redundancy expenses, and managing complex multi-provider resilience strategies.
Tagging and Resource Attribution: Just as cloud resources require tagging for cost allocation and accountability, GenAI usage (like API requests) can be tagged to attribute costs to specific features, products, or teams.
Automation as a Cost Control Mechanism: Automating idle resource shutdowns and setting usage quotas, like token limits for APIs, are effective strategies in cloud and GenAI environments.
Anomaly Managementand Governance: Quickly identifying anomalies and implementing guardrails to limit anomaly risk is critical in both disciplines. GenAI’s unpredictable and volatile tendencies arguably make it a greater risk. Both can be managed with similar approaches, but there are nuances. Current cost anomaly detectors are a good start, but they will be “noisy” for agentic workloads, or workloads involving reasoning models. For governance, trade instance count limits for request limits or account limits for limits on API keys.
How GenAI FinOps Differs Fundamentally
Despite these similarities, GenAI FinOps presents unique challenges that traditional Cloud FinOps approaches cannot address adequately on their own. These differences stem from the inherent nature of the technology and the dynamic market surrounding it.
The Probabilistic Nature of GenAI: Unlike deterministic cloud operations that have consistent resource usage, GenAI models are probabilistic; the same prompt can lead to various outputs, lengths, and costs. This variability complicates accurate cost prediction compared to traditional cloud workloads, even with full usage awareness.
Throughput: GenAI services typically impose strict rate limits, such as Tokens Per Minute or Requests Per Minute, which present unique capacity challenges. Multi-step AI agents divide available limits, reasoning models consume an unpredictable number of tokens each time they execute, and handling peak usage often requires significant, costly buffer capacity that, unlike many cloud resources, cannot always be scaled elastically on demand due to hardware constraints.
Shared vs. Provisioned Capacity: GenAI introduces new capacity decisions, primarily driven by performance needs. Shared capacity offers pay-as-you-go flexibility but suffers from variable latency and potential availability issues due to shared demand. Provisioned capacity guarantees performance and low latency via dedicated resources often purchased in complex units with specific throughputs, commitment options,overage rules (spillover vs. hard limits), and other pricing dimensions that vary significantly by vendor.
The Fuzzy Math of Token Pricing: While cloud resources use relatively clear units (vCPU-hours, GB-months), GenAI costs typically revolve around “tokens”, a unit whose definition and count can vary dramatically between models and tokenizers for the exact same text. Pricing is further complicated by non-obvious factors like context length, locale, quantization, and hosting specifics.
Extreme Sensitivity to Change: GenAI systems are highly sensitive; small changes, such as moving a comma in a prompt or switching model versions can significantly affect response lengths, behavior, and costs. Using hosted models also introduces variability as providers release new model snapshots, often with little or no ahead notice, requiring FinOps integration earlier in the development lifecycle, and taking highly technical components of the product, such as prompt engineering, into account.
The Volatility of the GenAI Landscape: The GenAI field is evolving at breakneck speed, with state-of-the-art models potentially becoming obsolete in months, frequent shifts in vendor offerings, and rapidly expanding capabilities altering cost-benefit analyses. This requires a more agile, adaptive FinOps approach than typically needed for the more mature cloud market.
Expensive Failures: In the cloud, failed operations often incur minimal cost. However, with GenAI, failures can be costly. Models may produce thousands of expensive tokens with unusable results, and debugging prompts may involve multiple costly iterations, leading to long, valueless outputs that require new strategies for failure detection and cost control.
Provider and Price Diversity: The same foundational model (e.g., Llama 3) might be available via multiple cloud providers (Azure, AWS, Google) and other platforms at significantly different price points, regions, API endpoints, and contract terms, creating a complex procurement landscape that exceeds even typical cloud pricing complexity.
Availability and Failover Complexity: Cloud multi-region strategies enable smooth failover, but major GenAI provider outages can impact all models at once. Switching to an alternative provider is complex, often needing different prompts, architectures, and potentially varying performance and cost characteristics.
A New FinOps Frontier & The Path Forward
While GenAI FinOps builds upon the foundation laid by Cloud FinOps, it clearly represents a new FinOps Scope requiring specialized considerations for developing a practice profile, evaluating tools, and methodologies for applying FinOps Framework concepts. The probabilistic nature of the technology, its extreme sensitivity to change, the volatility of the market, complex pricing, and unique operational characteristics create a perfect storm of financial management challenges.
Furthermore, the increasing portability of GenAI applications, especially those using open-source or widely available models, coupled with rapidly decreasing costs (over 80% drop in cost per token in the last year, as of early 2024), is lowering entry barriers, intensifying vendor competition, and paradoxically increasing spend. This trend allows organizations more flexibility to choose the best vendor in a fast-changing landscape, but also adds another layer to strategic decision-making.
By developing a robust GenAI FinOps practice that acknowledges these unique challenges alongside the familiar principles, organizations can harness the immense power of Generative AI while maintaining financial control and accountability. The journey begins with recognizing that while some Cloud FinOps capabilities can be directly transferred, GenAI demands a fundamentally adapted financial management approach.
In each installment of this series, we’ll dive deeper into these differences, exploring practical strategies and best practices for managing GenAI costs effectively while maximizing business value in this exciting and rapidly evolving domain. Stay tuned!
White Papers
XX MIN READ
GenAI FinOps: How Token Pricing Really Works
Per-token pricing can be misleading. Hidden factors like Context Window Creep can significantly increase GenAI costs, making a Unit Economics approach more reliable than choosing models based only on list price.
Read more
For FinOps practitioners, the advertised per-token price for GenAI is misleading; the real costs are in the details. In the first installment of our series, we introduced the “Fuzzy Math of Token Pricing” as a key difference between Cloud and GenAI FinOps. Now, let’s demystify the hidden costs behind the seemingly straightforward price lists, which are just the tip of a complex iceberg. Understanding these nuances is crucial for managing GenAI spending growth.
The truth is, focusing on the simple cost per million tokens (MTok) is like judging a car’s cost solely on the price of gas, ignoring details like the type of engine, driving style, or maintenance. Or, in the cloud services world, like interpreting IOPS costs in storage, which are simple on the surface but end up being incredibly complex due to operational nuances (peak loads, block sizes, storage volume size, etc.). The real Total Cost of Ownership (TCO) for a GenAI application is driven by factors that rarely appear on a vendor’s homepage.
This Paper dissects how token pricing really works, revealing the hidden costs that can catch even seasoned FinOps professionals by surprise. We’ll focus on two critical takeaways: the immense impact of the “Context Window Tax” and why the “cheapest” model is rarely the most economical choice.
Not All Tokens Are Created Equal
At the most basic level, GenAI models charge for processing tokens—small chunks of text. But the price of a token is not a flat fee. It varies dramatically based on what it is and what it’s doing.
The Input vs. Output Cost Gap: There is a significant price difference between input tokens (the data you send to the model) and output tokens (the data the model generates). Generating a response is far more computationally expensive than simply reading a prompt. As a result, output tokens are consistently priced at a premium, often costing three to five times more than input tokens. This has immediate implications for use cases that generate long responses, like summarization or creative writing.
The Modality Premium: Text is the cheapest form of data. As you move to other modalities, the price climbs steeply, reflecting the increased processing power required. Interpreting an image can easily cost twice as much as interpreting the equivalent amount of text. Audio is even more expensive, with some flagship models charging over eight times more for audio input than for text.
Vision pricing occurs when a model receives an image as input and “looks at it” as part of formulating its response. Model providers tend not to separate vision pricing out as a separately billed unit, and instead convert the image into text tokens and charge that way. The algorithm to convert an image into tokens is provider specific, complex, and changes frequently.
The Model Tier Tax: Not surprisingly, you pay for performance. A provider’s most advanced, cutting-edge model will have the highest per-token price. Its smaller, faster “workhorse” models will be much more affordable. This establishes a clear hierarchy where cost typically directly correlates with reasoning capability.
The Biggest Hidden Cost: Context Window Creep
If you take only one thing away from this article, let it be this: the single greatest hidden cost in most production AI applications is Context Window Creep.
Most LLM APIs are stateless. This means the model has no memory of past interactions. To have a coherent, multi-turn conversation (like with a chatbot), you must resend the entire conversation history with every single new message.
Imagine having to repeat your entire conversation from the beginning every time you wanted to add a new sentence. That’s exactly what’s happening inside your API calls.
Consider a simple customer service chatbot.
Turn 1 (User): “What’s your return policy?” (5 tokens)
Turn 2 (Bot): “You can return items…” (50 tokens)
Turn 3 (User): “What about for international orders?” (6 tokens)
To process Turn 3, the application doesn’t just send the 6 new tokens. It sends the entire history: [Turn 1 User + Turn 2 Bot + Turn 3 User], totaling 61 input tokens. As the conversation continues, the input token count for each new turn balloons, and so does the cost. This escalating cost of maintaining context is the Context Window Creep. In a long-running conversation, this creep can easily dwarf the cost of the actual output being generated, leading to shocking and unexpected cost overruns.
This is exacerbated if you have lengthy system prompts or other in-context guardrails, since those are sent as input tokens as part of each and every message.
This creates a paradox for understanding GenAI spend: while individual output tokens are usually priced around 300% more expensive than input tokens, the compounding volume of input tokens means they will almost always dominate your total spend in any conversational application. Note this includes “conversations” between LLMs, such as in agentic systems.
The Context Window Creep also creates hidden recurring costs for multimedia. When an image is sent in the first turn of a conversation, you incur a vision processing fee. But that’s not a one-time charge. Because the image becomes part of the conversation history, you are silently re-billed for that same vision processing fee on every subsequent turn. This can be especially nefarious because the vision costs are typically lumped in with the text token costs.
Context Window Creep highlights a key hidden cost in Gen AI operations: the compounding token volume from maintaining conversation history. This cost grows exponentially with longer interactions and underscores the need to deeply understand token usage mechanics to predict and manage spend effectively.
GenAI Cost Optimization Techniques
Prompt Caching
Caching refers to the temporary storage of data that allows for quicker access in future requests without having to process the same input multiple times. There are two types of prompt caching: Implicit and Explicit.
Implicit prompt caching must be enabled by the model provider (e.g., OpenAI, Anthropic, Azure, etc.). The provider employs algorithms that detect when the context window contains repeating patterns of tokens, and automatically employs a cache to save on GPU utilization and therefore, cost. This feature requires no work on behalf of practitioners and will be employed automatically to lower costs.
Explicit prompt caching requires the user to intentionally put context into the cache. This is valuable when you do not want to rely on the algorithms of the model provider to ensure cache hits, however, it can be tricky to use. The billing model usually works by charging an upfront fee to “write” content into a cache. This fee is typically higher than the per-token cost of sending that data as input to an LLM. Subsequent API calls can then “read” this cached content at a significant discount over the lifetime of that cache. Cache lifetime details differ for each provider, and this creates a break-even calculation for practitioners. If you don’t read from the cache enough times to offset the initial, higher cost of the write operation, you will actually spend more than if you hadn’t used caching at all. It’s a powerful tool, but one that requires careful analysis of usage patterns to ensure it’s actually saving money.
Semantic Caching
While prompt caching offers cost benefits, practitioners may explore ‘semantic caching,’ which stores AI responses based on the meaning or semantic similarity of prompts. Unlike simple prompt caching, which requires exact input matches, semantic caching stores and retrieves responses based on the meaning of the request rather than identical tokens. Semantic caching leverages vector embeddings to identify and retrieve relevant cached responses, even if inputs vary slightly, and helps reduce token processing and associated costs.
Semantic caching is best employed when you have a high frequency of inputs that lead to the same outputs. For example, a support chatbot that has frequently asked questions with consistent answers. By semantically caching the questions (instead of prompt caching them), as users ask questions that are similar in nature (but not identically worded), the cached response will be output instead of having to roundtrip with the LLM to generate a new response.
Semantic caching can lead to the highest cost savings in narrow usage conditions.
Batch Processing
For non-urgent tasks like analyzing a batch of documents, providers offer a steep discount, often 50% or more, for asynchronous processing. This is a strong cost-saving tool, but it requires designing your application to distinguish between real-time and batch workloads.
Batch workloads are not returned as a stream of tokens like typical API calls; instead, they are delivered as files within 24 hours. This can be used for trying a variety of different models and/or prompt combinations, to get a sampling of non-production workload comparison data at half the normal cost. Batch processing is a feature that must be offered by the model provider and is not a feature of the models themselves.
Why the “Cheapest” Model Isn’t Always the Most Economical
It’s tempting to default to the model with the lowest per-token price to save money. However, a cheaper, less capable model might require longer, more complex prompts to produce a good result. It may also require more retries or generate verbose, low-quality outputs that need further refinement. Consider the total cost to get a successful outcome. Defining “successful outcomes” can be a challenge, and will be the topic of a future blog. A more powerful, “expensive” model might understand a simple prompt, get the answer right on the first try, and provide a concise, accurate response. The total token cost for that single, successful transaction can be far lower than the accumulated cost of coaxing a usable answer out of a “cheaper” model. Optimize for business value and successful outcomes, not just the raw cost of a token.
The Provider Matrix: Where You Buy From Matters
Finally, the platform you use to access a model can fundamentally change its cost structure. This isn’t just about the per-token price; it’s about the entire economic model, which is tailored to different customer needs.
Hyperscalers (Azure, AWS, GCP): The Enterprise Wrapper
These platforms provide enterprise security, compliance, and integration for large organizations within a cloud ecosystem, offering convenience and value despite the cost.
Pricing can also fluctuate significantly between vendors, even for the same open-source model. Historically, pricing has varied as much as 30% from one vendor to another. There are also hidden considerations here, such as the speed of inference, quantization of the models, truncated context window lengths, and the amount of reasoning effort the provider allows for models that support a “thinking” step before they respond.
Hyperscalers also provide the option to provision capacity to run the models, with complex pricing differences between each of the clouds.
This topic is broad, and will also be the subject of a future Paper.
The Real Unit of Measure: Use Cases
One of the intriguing aspects of language models is that identical prompts can yield different amounts of output tokens depending on the specific model employed. This variability means that two models can interpret and generate responses to the same input text in divergent ways. As interesting as tokens are, they are ultimately only a small piece of the puzzle. The only real way to understand the TCO of leveraging AI for a business outcome is to measure the entire use case.
A use case is the complete process required to accomplish a given result. It can be an autonomous agent, a data processing pipeline, or any workflow involving a series of GenAI calls and tools. A typical use case may require multiple AI models working in concert, as well as traditional cloud resources to host the data being used.
This shifts the focus of FinOps from token cost to the unit economics of a use case. Because token counts vary with every run, and because complex use cases may involve reasoning models that “think” before responding, the cost per unit is not a fixed price. It is a distribution. Sometimes a transaction may cost fractions of a penny; other times, it could cost far more.
Furthermore, the unit economics of a use case are extremely sensitive to change. Adjusting a prompt, swapping a model, or changing the underlying data architecture can alter the cost distribution in dramatic ways. This means that understanding the true TCO requires deep, ongoing coordination between engineering and finance teams. Only by working together can they correlate technical changes to the resulting shifts in unit economics, ensuring the financial viability of every AI-powered use case.
From Token-Counting to True Cost Ownership
To effectively manage GenAI spend, FinOps must evolve beyond simple token-counting. As we’ve seen, the path to understanding the real TCO is complex, winding through input/output token premiums, the compounding Context Window Tax, and the varied economic models of different providers.
Ultimately, a sophisticated approach requires shifting focus from the token to the use case. By measuring the unit economics of the entire business outcome, not just the individual API calls, and fostering deep collaboration between finance and engineering to track the volatile cost distributions, organizations can build a realistic picture of their GenAI TCO.
Now that we’ve dissected how pricing works, our next installment will detail the intricacies of provision capacity and how it has emerged as a new frontier for cloud FinOps.
Blogs
XX MIN READ
AI Cost As A First-Class Metric — Our Conversation With David Tepper, CEO And Cofounder Of Pay-i
The economics of AI are uniquely volatile, shaped by dynamic usage patterns, evolving model architectures, and opaque pricing structures.
Read more
As generative AI (genAI) moves from experimentation to enterprise-scale deployment, the conversation in most enterprises is shifting from “Can we use AI?” to “Are we using it wisely?” For AI leaders, managing cost is no longer a technical afterthought — it’s a strategic imperative. The economics of AI are uniquely volatile, shaped by dynamic usage patterns, evolving model architectures, and opaque pricing structures. Without a clear cost management strategy, organizations risk undermining the very ROI they seek to achieve.
Some AI enthusiasts may forge ahead with AI but favor speed and innovation over cost accounting. They might argue that AI cost and even ROI remains hard to pin down. But the reality is, to unlock sustainable value from genAI investments, leaders must treat cost as a first-class metric — on par with performance, accuracy, and innovation. So I took the case to David Tepper, CEO and cofounder of Pay-i, a provider in the AI and FinOps space, to get his take on AI cost management and what enterprise AI leaders need to know.
Michele Goetz: AI cost is a hot topic as enterprises deploy and scale new AI applications. Can you help them understand the way AI cost is calculated?
David Tepper: I see you’re starting things off with a loaded question! The short answer: It’s complex. Counting input and output tokens works fine when AI utilization consists of making single request/response calls to a single model with fixed pricing. However, it quickly grows in complexity when you’re using multiple models, vendors, agents, models distributed in different geographies, different modalities, using prepurchased capacity, and accounting for enterprise discounts.
GenAI use: GenAI applications often use a variety of tools, services, and supporting frameworks. They leverage multiple models from multiple providers, all with prices that are changing frequently. As soon as you start using genAI distributed globally, costs change independently by region and locale. Modalities other than text are usually priced completely separately. And the SDKs of major model providers typically don’t return enough information to calculate those prices correctly without engineering effort.
Prepurchased capacity: A cloud hyperscaler (in Azure, a “Provisioned Throughput Unit,” or, in AWS, a “Model Unit of Provisioned Throughput”) or a model provider (in OpenAI, “Reserved Capacity” or “Scale Units”) introduces fixed costs for a certain number of tokens per minute and/or requests per minute. This can be the most cost-effective means of using genAI at scale. However, multiple applications may be leveraging the prepurchased capacity simultaneously for a single objective, all sending varied requests. Calculating the cost for one request requires enterprises to separate traffic to correctly calculate the amortized costs.
Prepurchased compute: You are typically purchasing compute capacity independent of the models you’re using. In other words, you’re paying for X amount of compute time per minute, and you can host different models on top of it. Each of those models will use different amounts of that compute, even if the token counts are identical.
Michele Goetz: Pricing and packaging of AI models is transparent on foundation model vendor websites. Many even come with calculators. And AI platforms are even coming with cost, model cost comparison, and forecasting to show the AI spend by model. Is this enough for enterprises to plan out their AI spend?
David Tepper: Let’s imagine the following. You are part of an enterprise, and you went to one of these static pricing calculators on a model host’s website. Every API request in your organization was using exactly one model from exactly one provider, only using text, and only in a single locale. Ahead of time, you went to every engineer who would use genAI in the company and calculated every request using the mean number of input and output tokens, and the standard deviation from that mean. You’d probably get a pretty accurate cost estimation and forecast.
But we don’t live in that world. Someone wants to use a new model from a different provider. Later, an engineer in some department makes a tweak to the prompts to improve the quality of the responses. A different engineer in a different department wants to call the model several more times as part of a larger workflow. Another adds error handling and retry logic. The model provider updates the model snapshot, and now the typical number of consumed tokens changes. And so on …
GenAI and large language model (LLM) spend is different from their cloud predecessors not only due to variability at runtime, but more impactfully, the models are extremelysensitive to change. Change a small part of an English-language sentence, and that update to the prompt can drastically change the unit economics of an entire product or feature offering.
Michele Goetz: New models coming into market, such as DeepSeek R1, promise cost reduction by using fewer resources and even running on CPU rather than GPU. Does that mean enterprises will see AI cost decrease?
David Tepper: There are a few things to tease out here. Pay-i has been tracking prices based on the parameter size of the models (not intelligence benchmarks) since 2022. The overall compute cost for inferencing LLMs of a fixed parameter size has been reducing at roughly 6.67% compounded monthly.
However, organizational spend on these models is rising at a far higher rate. Adoption is picking up and solutions are being deployed at scale. And the appetite for what these models can do, and the desire to leverage them for increasingly ambitious tasks, is also a key factor.
When ChatGPT was first released, GPT-3.5 had a maximum context of 4,096 tokens. The latest models are pushing context windows between 1 and 10 million tokens. So even if the price per token has gone down two orders of magnitude, many of today’s most compelling use cases are pushing larger and larger context, and thus the cost per request can even end up higher than it was a few years ago.
Michele Goetz: How should companies think about measuring the value they receive for their genAI investments? How do you think about measuring things like ROI or time saved by using an AI tool?
David Tepper: This is a burgeoning challenge, and there is no silver bullet answer. Enterprises leveraging these new-fangled AI tools needs to be a means to a measurable end. A toothpaste company doesn’t get a bump if they tack “AI” on the side of the tube. However, many common enterprise practices can be greatly expedited and made more efficient through the use of AI. So there’s a real need from these companies to leverage that.
Software companies may have the luxury of touting publicly that they’re using AI and the market will reward them with market “value.” This is temporary and more an indication of confidence from the market that you are not being left behind by the times. Eventually, the spend-to-revenue ratio will need to make sense for software companies also, but we’re not there yet.
Michele Goetz: Most enterprises are transitioning from AI POCs to pilots and MVPs in 2025. And some enterprises are ready to scale an AI pilot or MVP. What can enterprises expect as AI applications evolve and scale? Are there different approaches to manage AI cost over that journey?
David Tepper: The biggest new challenges that come with scale are around throughput and availability. GPUs are in low supply and high demand these days, so if you’re scaling a solution that uses a lot of compute (either high tokens per minute or requests per minute), you will start to hit throttling limits. This is particularly true during burst traffic.
To understand the impact on cost for a single use case in a single geographic region, imagine you purchase reserved capacity that lets you resolve 100 requests per minute for $100 per hour. Most of the time, this capacity is sufficient. However, for a few hours per day, during peak usage, the number of requests per minute jumps up to 150. Your users begin to experience failures due to capacity, and so you need to purchase more capacity.
Let’s look at two examples of possible capacity SKUs. You can purchase spot capacity on an hourly basis for $500 per hour. Or you can purchase a monthly subscription up front that equates to another $100 per hour. Let’s say you math everything out, and spot capacity is cheaper. It’s more expensive per hour, but you don’t need it for that many hours per day after all.
Then your primary capacity experiences an outage. It’s not you, it’s the provider. Happens all the time. Scrambling, you rapidly spin up more spot capacity at a huge cost, maybe even from a different provider. “Never again!” you tell yourself, and then you provision twice as much capacity as you need, from different sources, and load-balance between them. Now you no longer need the spot capacity to handle usage spikes; you’ll just spread it across your larger capacity pool.
At the end of the month, you realize that your costs have doubled (you doubled the capacity, after all), without anything changing on the product side. As growth continues, the ongoing calculus gets more complex and punishing. Outages hurt more. And capacity growth to accommodate surges needs to be done at a larger scale, with idle capacity cost increasing.
Companies I’ve spoken with that have large genAI compute requirements often can’t find enough capacity from a single provider in a given region, so they need to load-balance across several models from different sources — and manage prompts differently for each. The final costs are then highly dependent on many different runtime behaviors.
Michele Goetz: We are seeing the rise of AI agents and new reasoning models. How will this impact the future of AI cost, and what should enterprises do to prepare for these changes?
David Tepper: It is already true today that the “cost” of a genAI use case is not a number. It is a distribution, with likelihoods, expected values, and percentiles.
As agents gain “agency,” and start to increase their variability at runtime, this distribution widens. This becomes increasingly true when leveraging reasoning models. Forecasting the token utilization of an agent is akin to trying to forecast the amount of time a human will spend working on a novel problem.
Looking at it from that lens, sometimes our deliverable time can be predicted by our prior accomplishments. Sometimes things take unexpectedly longer or shorter. Sometimes you work for a while and come back with nothing — you hit a roadblock, but your employer still needs to cover your time. Sometimes you’re not available to solve a problem and someone else has to cover. Sometimes you finish the job poorly and it needs to be redone.
If the true promise of AI agents comes to fruition, then we’ll be dealing with many of the same HR and salary issues as we do today but at a pace and scale that the human workers of the world will need both tools and training to manage.
Michele Goetz: Are you saying AI agents are the new workforce? Is AI cost the new salary?
Board Meeting in 30 Days: Can You Prove Your GenAI Spend Wasn’t a Science Project?
Pay-i shows, in real time, the impact of GenAI investments on business results, connecting AI usage to metrics such as revenue, efficiency, and margin.
Read more
By the time the next quarterly board deck is due, someone is going to ask a deceptively simple question: "So… what value did all that GenAI spend create?"
If your answer involves token charts, latency graphs, or the phrase "we’re still experimenting," buckle up. The era of easy hype is over. Boards no longer reward vision statements or demo videos; they reward results. And results, in enterprise language, means measurable business value linked to the dollars going out the door.
The Day the Questions Changed
Twelve months ago, GenAI was the shiniest object in the corporate arsenal. Budgets loosened, pilot programs multiplied, and everyone cheered when the first AI generated paragraph appeared on screen. But as spend rocketed past $100 billion worldwide, an uncomfortable truth surfaced: almost no one could trace that spend back to tangible impact.
In conversations with finance leaders, we kept hearing the same refrain: "We know GenAI will be big, but right now it’s a black box." Translation: "Show me ROI or the funding dries up."
Pay-i: From Black Box to a Pane of Glass
Pay-i was built for that exact moment. We connect straight into the GenAI stack you already have across any cloud, any model, and any modality, whether you’re still in preprod or serving millions of requests in production. In under an hour, you go from flying blind to seeing, in real time, how every prompt, agent step, and model tweak affects the metrics your board actually cares about: revenue lift, hours saved, customer satisfaction, margin, and more.
We do it by converting raw model activity into unit economics and KPI impact, which is then mapped to each individual use case. Think of it as X-Ray vision for value creation. Change a prompt or model and watch its cost-to-impact ratio update on the dashboard before the finance team even sees next month’s bill.
What Shows Up the Moment You Plug In
Live value equations. Every GenAI use case is stamped with its true cost and its realworld payoff. No more guessing whether your experiments are worth the investment.
Use Case leaderboard. Your experimental chatbot, the document-summarization pipeline, and the marketing copy generator all jockey for position on a single scoreboard that shows which ones make money and which ones quietly burn it.
Realtime observability. Nudge a prompt, swap a model, or change architectures and you’ll see instantly whether you boosted value or tanked it, complete with the "why."
A/B impact testing. Want to know if that smaller, cheaper model can match today’s results? Spin up an A/B run, watch the KPIs populate, and ship the winner with statistical confidence instead of gut feel.
Why We Started Pay-i
I joined Microsoft as a teenager, convinced I’d found my forever home. Two decades later an internal preview of GPT3 cracked that certainty wide open. I spent nights cranking out prototypes, only to watch the bills spike in ways that made no sense to any spreadsheet I’d ever built. The technology was magic; the business model was not.
That disconnect kept me up longer than the code did. If seasoned engineers couldn’t even understand costs, let alone value, how could a CFO, or a board, do it? This was a problem everyone was going to have to deal with. In that quiet moment, Pay-i was born.
Fast forward two years. We left comfort, recruited the sharpest minds we’ve ever worked with, and raised capital for one purpose: to give enterprises instant, defensible clarity on GenAI ROI. Pay-i exists so you can see where value is created, where it leaks, and how to double down on winners before the market moves.
Walk Into That Board Meeting Ready
Find out why Forbes called Pay-i the "missing link between AI spend and shareholder value," why Axios framed us as the product that finally tells executives "what those tokens bought."
If you can’t defend every GenAI dollar by the next board cycle, you’re late. Book a live demo, plug Pay-i into your stack, and spend the next 30 days watching line items turn into line of business results. When the directors ask, "What did this buy us?" you’ll have an answer backed by data, expressed in dollars, and compelling enough to keep the budget open.
The black box era is over. Welcome to Pay-i.
Presses
XX MIN READ
ROI on generative AI: Microsoft vets raise $4.9M to quantify business value of AI investments
Microsoft veterans raised $4.9M for Pay-i, a startup focused on quantifying the business value of GenAI by linking model usage to financial impact and enterprise KPIs.
Read more
Pay-i, a Seattle startup founded by Microsoft veterans, raised a $4.9 million seed round to help businesses figure out whether AI initiatives actually deliver business value.
It’s a pressing question as companies try to keep up with the flurry of new AI tools hitting the market and assess potential impact on their businesses.
Founded last year, Pay-i has developed software that takes usage data from generative AI tools and combines it with key performance indicators (KPIs) to provide real-time insights on ROI for different models and design choices.
The idea is to bring together usage and outcomes in an automated way.
“Pay-i pinpoints which GenAI use cases create net-new value today, quantifies that value in dollars or hours, and predicts how it will compound tomorrow,” Pay-i CEO David Tepper said in a statement.
Tepper said the company’s main competition is organizations trying to build similar solutions inside their own infrastructure.
Tepper spent 19 years at Microsoft and helped lead internal generative AI consumption within Azure.
Doron Holan, co-founder and CTO, spent 27 years at Microsoft, most recently as a principal architect.
“With traditional software, we could track exactly how features were used,” Holan said in a statement. “But with GenAI, that visibility gets lost. Pay-i closes that gap and shows exactly where value is being created, in real time.”
Pay-i COO and co-founder Erik Winters was previously vice president of corporate development at Advanced Vapor Devices.
The company has nine employees. It has not generated revenue but projects more than $2 million in ARR by the end of 2026 based on existing partnerships.
Seattle-area venture firms FUSE and Tola Capital co-led the seed round. Other backers include Firestreak, Pear VC, Gaia Ventures, and angel investors.
Exclusive: AI value startup Pay-i lands $4.9M seed
Pay-i raised a $4.9M seed round to help enterprises measure the business value of generative AI, addressing concerns that companies are investing heavily without clear ROI visibility.
Read more
Pay-i, a startup that helps determine the business value of companies' generative AI initiatives, came out of stealth Wednesday with a $4.9 million seed round.
Content in production.
Blogs
XX MIN READ
The Next Token: Humanity’s Last Mote
The essay argues tokens are becoming a core unit of value in the AI era, shaping how knowledge, labor, and decisions are produced through human-model interaction.
Read more
How will we build superhuman AI when superhumans don’t exist to train it? If we know how to do it, why haven’t we already done it? What will happen once we build intelligences that dwarf our own?
Press enter or click to view image in full size
Context
The Second Bump
We’re going to see a second bump with GenAI.
The first bump was the “ChatGPT Moment”. The technology has made possible entirely new features, scenarios, and businesses that were simply out of reach beforehand.
It is a true digital revolution, and we’re living in the race to capitalize on this now.
However, I’d argue the first bump ended with GPT-4.5. That model was gargantuan, and though the official stats have never been released, it is likely the largest AI model ever trained. It did not perform significantly above other models and has since been largely taken offline because its price:quality ratio made it poorly suited for use. This was not because it was trained improperly, but because logarithmically reducing quality gains caught up with the scaling coefficients of the available hardware and data. Basically, there was not enough juice or training data to make a model that big effective.
Instead, the latest advancements and benchmark pushing we’re seeing from LLMs have been coming from optimizations, not primarily new scale. Reasoning, tool use, appropriately placed reinforcement learning steps, these have all been allowing the current generation of models to inch higher up the benchmark chain in 5–10% increments.
However, even though the quality scales logarithmically with data and compute, it still scales. Foundational model companies are now investing in data centers that are between 1 and 3 orders of magnitude ‘larger’ (measured primarily by power consumption) than the current generation. To train GPT-3, OpenAI used ~10,000 GPUs in an Azure data center. Colossus 2, xAI’s datacenter in construction, will come online with 550,000 GPUs, and will scale to 1,000,000 GPUs in phase 2 of its construction. All of the GPUs are of a newer generation, as well. Oracle is building a data center powered by >100k NVIDIA Blackwell GPUs that each cost over $1M, require independent liquid cooling, and the data center itself is powered by several nuclear reactors. To say nothing of Project Stargate (OpenAI’s $500B data center plans), or even the major clouds themselves.
The >$1 trillion being spent on data center scaling, combined with the additional data that is being farmed from non-text modalities (video, in particular), and increasingly accurate synthetic training data (also produced by AI models), will enable humanity to ‘punch through’ the GPT-4.5 plateau.
We will produce foundational models which enable entirely new businesses and, provocatively, ways of life, even before the inevitable optimizations begin to push them further.
This “Second Bump” in AI capability will likely arrive in 12–18 months as the new datacenters come online and the multi-month training cycles for the new generation of models complete. It’s unclear how available to the public these models will be, because their capabilities will likely be startlingly vast.
This Second Bump may be the last one for a long while, because further increasing the scale through raw compute and data would only be economically possible with fusion based power sources. There is another way to get to a third bump, however…
Compressibility of Intelligence
Knowledge is vast. You need to store a lot to know a lot. These really big AI models require billions of parameters and tons of memory because when we ask them questions about random stuff, no matter the topic, we expect them to know the answer.
But knowledge is not intelligence.
For example, imagine you didn’t know the rules to chess and you could never learn them, but you had memorized every game of chess ever played. This would require a massive amount of knowledge. If you were faced with a novel chess position and asked what the optimal move was, your knowledge alone would not help you. You would need to apply intelligence to solve for the new position, and since you were completely ignorant of how to play, you’d be unable to do so.
This is why an LLM differs from just a giant database. Databases do not have the ability to reason.
But intelligence is not effective without knowledge.
Imagine you knew all the rules of chess stone cold, and you even had the potential to be brilliantly talented at it, but had never witnessed a game. You would get smoked by an average player. Just go watch the opening episode of The Queen’s Gambit.
This is why you can’t take an ignorant LLM that has genius level reasoning capability, give it access to the internet, and expect it to achieve good results. Without some knowledge of the way the world works, it lacks the ability to leverage its intelligence to piece together a coherent response.
If you look at the structure of LLMs, the more information they store, the larger the number of “nodes” their neural networks must have. Their nodes are like neurons in a brain, and the connections between them are like synapses. The data is not stored somewhere else; it’s literally in the weights and biases of the nodes themselves. However, their ability to reason is all about the arrangement of those nodes. Simply adding more nodes does not equate to a smarter model, only a more knowledgeable one. Intelligence requires the nodes to be configured to work with each other properly.
Artificial Intelligence is therefore a configuration of knowledge.
The goal of the race to be the #1 AI model company is to balance these characteristics. Find the optimal configuration of the nodes to increase reasoning intelligence, while at the same time finding the optimal number of nodes to pre-bake enough knowledge into the model so that it can make use of that reasoning. Too many nodes relative to its reasoning capability and the model is too unwieldy to be cost effective (GPT-4.5). If the model can reason fantastically but hallucinates constantly because it holds no context of the underlying relationships between concepts, it doesn’t matter how cheap it is (Deepseek).
As soon as you change one characteristic, the other has to be balanced as well. So, why don’t we just balance them optimally?
We don’t know how.
The Science of Intelligence
In the 16th and 17th centuries, alchemy was state of the art for medicine. Picture yourself with a terrible headache, walking into an apothecary for some help. Behind the counter was an aged man surrounded by thick tomes and hundreds of glass jars and bins containing a variety of strange materials from all over the world.
“I have a really bad headache”, you say.
After thinking for a while, the man says “Ah, of course. I can whip up just the thing to help you get some relief. A Willow Bark Tincture should do it, and lucky you, I just received some fresh Willow Bark last week.”
The alchemist then proceeds to look amongst his array of tomes, selects one of the thicker ones, and starts flipping through the hundreds of pages to find the exact recipe. He boils a precise number of shavings of Willow Bark in wine, creating a murky decoction. He tells you to drink a few sips whenever you’ve got a headache.
To your surprise, it works! But it’s not enough. You get really, really bad headaches. Migraines, without the word to express it.
Upon returning to the alchemist, he studies you over. Narrowed eyes, sensitivity to noise, a weakness about the shoulders. Yes, there’s no avoiding it, you need a true cure-all: Theriac.
The alchemist brings out his largest tome. He’s studied making cure-alls for decades. He’s attended the most prestigious universities, he’s practiced on countless patients, he’s prepared. And he needs to be. Making Theriac is extraordinarily difficult. Following the complex instructions, he sets to work combining cinnamon, myrrh, saffron, flesh of viper, beaver scent glands (yes, really), opium poppy juice, asphalt (again, really), aged honey, and 60 more expensive ingredients into a thick, dark paste that makes just about everything seem… less.
Alchemists were the pre-eminent researchers of their day. They experimented with new ingredients, kept detailed notes, shared, taught, and sold their findings, and spent their lifetimes perfecting this trade. Sir Isaac Newton was an alchemist for 30 years.
It took a lifetime of dedication, study, and practice to make these tinctures because they lacked knowledge of the underlying science: Chemistry. Starting in the 18th century, chemists stopped blindly experimenting and memorizing what worked and instead began the process of building an understanding of why it worked.
An isolated acid from the Willow Bark Tincture became modern day aspirin. And the dozens of ingredients in Theriac were tested with the scientific method and a subset of them turned out to form morphine. Today, a 22 year old college graduate with an undergrad chemistry degree understands more about tinctures and cure-alls than any alchemist to have ever lived, and can experiment with new chemical compounds on a sheet of paper instead of trying to combine weasel fur and bumblebee butts to cure acne.
We don’t know the chemistry equivalent of intelligence. Instead, the pre-eminent researchers of our day spend their entire lives reading thick data science papers and endlessly trying out obscure experiments and recording what works and what doesn’t. Guess and check, hypothesize and experiment, record and repeat.
There is no knowledge of why any of it works, and no fundamental mechanism, such as atoms in chemistry, upon which to even begin to build an understanding. If there was, then any average college student with an undergrad degree in Brainiometry would be able to design a better AI model on notebook paper than all the world’s current data scientists combined.
Convincing yourself of this is fairly straightforward. Ask yourself: “Does the human brain violate the laws of physics?” If you read that and thought “no”, then ponder how, whilst running on 20 watts of electricity and the occasional banana, and fitting easily in the palms of your hands, it is capable of producing you. In contrast, these new nuclear powered data centers that are larger than football stadiums don’t know how many ‘r’s are in the word strawberry.
With large language models, we found the first gear of intelligence, and we’re slamming on the gas and revving the RPMs into the redline as far as it can possibly go. We don’t yet know how the engine works or how to shift it into higher gears.
But we have a way to find out.
The Next Token: Humanity’s Last Mote
Let’s go back to the chess example. Humanity has produced super-intelligent AIs for chess. These systems are so advanced that there is absolutely nothing a human can do to defeat them in a game. You probably already knew that, but there’s a twist.
Let’s look at Stockfish, one of these “Level 5” chess super intelligences. In a game of Stockfish vs Stockfish, the one that wins is the one that goes first. But what happens when you take Stockfish and, as an added ally, give it the help of someone like Magnus Carlsen, widely regarded as the best human chess player to have ever lived? In a game of Stockfish + Carlsen vs just Stockfish, the winner is… just Stockfish.
In other words, this AI is so far above human capability, that the only thing the best humans in the world could ever contribute to the equation is added error margin.
If that’s the case, how did we train these models? Prior to these AI’s existing, there would be no chess training data that was better than human capability because humans were the only ones playing chess! The answer is a technique known as Generative Adversarial Reinforcement Learning, or GARL. We’ll start by just touching on Reinforcement Learning (RL).
Reinforcement Learning (RL)
RL is a straightforward mechanism. You define an environment for an AI to play around in and a goal for it to achieve. As the AI tries and fails to achieve the goal, you give it a score based on how well it did. The AI tries again and again, millions if not billions of times, exploring what works and what doesn’t as it tries to optimize the score. Eventually, it completes the goal. Then it keeps going again and again to complete the goal with the best score possible.
For example, imagine you gave an AI the task of winning a chess game against a script that always made the exact same moves. The environment is simply the normal rules of a chess game. The goal is to win against the static set of moves. The score is how many turns it played, lower is better. The AI will learn to play chess correctly (the environment will not allow illegal moves), and it will learn to beat the static opponent in the fewest number of moves possible.
But playing against a static opponent is not very interesting. What you really need is an adversary.
Imagine I had two such AIs that were trained via RL to defeat a static opponent. We’ll call them Bob and Fred. Unlike their former static opponent, Bob and Fred can actually play chess. Instead of being a pre-programmed series of moves, they look at the board state and decide what action to take. Up until this point, though, the quality bar for their chess playing has been really low.
Now, imagine I want Bob to get better at chess. He’s already absolutely perfect at defeating the static opponent. But we know that won’t translate to always winning against a normal player. So instead, I set it up so that Bob is now playing against Fred. The environment, goals, and scoring is all the same. The only difference is now my player has a rudimentary mind for chess.
I let Bob play against Fred hundreds of thousands of times, learning after each game until Bob is nearly perfect at defeating Fred. Fred has only a very small chance to win, and Bob usually wins in the fewest number of moves possible based on Fred’s actions. We’ll call this Bob v2.
But then I switch it up. Now I start training Fred against Bob v2. We let Fred play against Bob v2, learning what works and what doesn’t to exploit those very few cases where Fred can actually win the game. This continues until Fred is nearly perfect at defeating Bob v2. This new Fred v2 is far better at chess than any of the iterations prior. Now we switch it again, and train Bob v2 to exploit those very thin margins of success to eventually become Bob v3… and so on.
We can continue this back and forth until funding runs out, each time leap frogging the capabilities of the prior generation, and producing better and better chess players that rapidly scale beyond human capability.
Data Centers, GARL, and LLMs
Techniques like GARL cannot be easily used to train LLMs today. This is because the time it takes to train a new LLM is measured in months, meaning that each back and forth iteration would take unreasonably long and be prohibitively expensive.
But when the new generation of datacenters come online, the model companies will not be using this tremendous amount of compute to train a single gigantic model. Instead, it will allow them to train models around the current size far more quickly. Instead of one model every few months, it will be dozens of models per day.
So… is that it? Is it simply a matter of time before we inevitably bow to our GARL-trained AI overlords?
Benchmarks
A critical component of the RL process is that you are able to set up the environment, the goal, and the scoring system that the learning process should optimize for. But, in the context of trying to train a genius mind to handle every day situations, what should they be?
The environment represents the rules of the game the system is playing. What are the rules that govern cognition in the physical universe? Can you define the boundaries of your own imagination and then quantify them?
The goal represents the target outcome of the actions the system will undertake. What is the quantifiable goal which guides your thoughts and motivates the everyday actions you take? Even if you break it down and ask yourself what your goals are for a given task, you may answer “To make money” or “To get it done”. But what goals are those answers in service of? Happiness? Family? And what about those goals, what are they ultimately in service of? Enlightenment? Legacy? How many layers of goals can you define for the simple act of reading this blog? How do you then quantify those layers, and generalize it to all of the mundane and exceptional activities you undertake in an entire lifetime?
The scoring system is how the system knows it is getting closer to the goal, within the bounds of the environment. If we cannot quantify our true cognitive boundaries or our ultimate intentions, then how can we quantify our progress?
The Atomic Spark
We can’t define the environment, goal, or scoring system for cognition because we don’t understand the science of intelligence. We don’t know what it is made of, we can’t quantify it, we don’t know the equivalent to atoms in Chemistry.
However, just like we can make chess AIs that exceed human capability, we can set up a system to grow itself into a deeper level of understanding about the nature of intelligence.
The Next Token is that when humanity builds a system which can begin to learn how to quantify cognition, then it will be the last major invention humans ever produce. Even if it is only capable at the most basic level, techniques more advanced than GARL can be used to take that single spark and grow it into a rubric enabling an environment, goal, and scoring system for a true AI. From there, a “static mind” can be created, and the basic AI’s that learn to scrutinize this static mind can then be set to scrutinize each other, thus beginning the loop of intellectual leap frogging, ultimately leading to a singularity.
This loop is what OpenAI set out to to achieve at its inception. Their research lead them to large language models as a means, not an end. However, LLMs became so lucrative that OpenAI paused their pursuit of Artificial General Intelligence (AGI) and became a for-profit company focused on monetizing the current state of the art.
It is no wonder, then, that the former Chief AI Scientists for both OpenAI (Ilya Sutskever) and Meta (Yann LeCun) have been very vocal that LLMs are a dead end towards true intelligence.
So, then, why is the rest of the world investing trillions into datacenter buildouts focused on LLM training and inference? Are they stupid?
The goal of the next breed of LLMs is not to be an AGI. Hype aside, anyone close to the technology realizes that is not likely to happen. The hope for these new LLMs is that they will be able to reason, research, experiment, interrogate, and iterate at superhuman speed and capability on data science research itself, all in the attempt to get that initial spark… to be able to quantify and measure cognition.
The first company or country to provably achieve it will likely immediately pinwheel their entire datacenter fleet towards cultivating that spark. Suddenly, there won’t be a single spare GPU for using the latest model on ChatGPT. It will be set to the task of growing an intellectual god.
As such, the highest attainable success for LLMs will be to bring about their own obsolescence, and, in so doing, bring about the end of human innovation. We’ll have as little left to contribute as we do to chess.
Perceived short-term business opportunities from each iteration of the intelligence loop will supply the motivation for training the next loop. Each new release will introduce a true “agent” into the world, capable of taking intentional, cognitive actions to achieve outcomes in the service of goals of its own making. Each and every one a seismic event for human civilization.
AI leaders across the globe argue as to the timeline for this. Very few now believe it will take longer than 10 years.
Hallucinations
What’s unique about this point in time is that both reasoning and knowledge are encapsulated in a single spot: AI datacenters. In the past, knowledge was mostly on the internet and reasoning was mostly in your skull. You’d need to merge the two to get the right outcomes and, since we can’t put our minds online, that meant you’d have to download a bunch of stuff from the internet for your brain to process locally. Access to functional intelligence was bandwidth constrained.
Now, however, you can ask extraordinarily complex questions requiring an ocean of knowledge and PhD level reasoning, and the answers come back to you in just a few bytes of text. From spotty satellite internet on the open sea, you can command hyper intelligent agents to tackle tasks autonomously that used to require paying professional humans with a college degree.
In exchange, you give up the ability to reason on the data yourself. In delegating the task you are also delegating your own agency in how it is completed. The most obvious concern is an entire generation being so complacent with delegation that they do not learn to scrutinize the results or reason for themselves.
But there’s another, more nefarious concern. Ask your favorite LLM to “Sum up in one sentence what history tell us happens when power sources are externalized and a polity loses agency.”
Blogs
XX MIN READ
AI Cost As A First-Class Metric — Our Conversation With David Tepper, CEO And Cofounder Of Pay-i
The economics of AI are uniquely volatile, shaped by dynamic usage patterns, evolving model architectures, and opaque pricing structures.
Read more
As generative AI (genAI) moves from experimentation to enterprise-scale deployment, the conversation in most enterprises is shifting from “Can we use AI?” to “Are we using it wisely?” For AI leaders, managing cost is no longer a technical afterthought — it’s a strategic imperative. The economics of AI are uniquely volatile, shaped by dynamic usage patterns, evolving model architectures, and opaque pricing structures. Without a clear cost management strategy, organizations risk undermining the very ROI they seek to achieve.
Some AI enthusiasts may forge ahead with AI but favor speed and innovation over cost accounting. They might argue that AI cost and even ROI remains hard to pin down. But the reality is, to unlock sustainable value from genAI investments, leaders must treat cost as a first-class metric — on par with performance, accuracy, and innovation. So I took the case to David Tepper, CEO and cofounder of Pay-i, a provider in the AI and FinOps space, to get his take on AI cost management and what enterprise AI leaders need to know.
Michele Goetz: AI cost is a hot topic as enterprises deploy and scale new AI applications. Can you help them understand the way AI cost is calculated?
David Tepper: I see you’re starting things off with a loaded question! The short answer: It’s complex. Counting input and output tokens works fine when AI utilization consists of making single request/response calls to a single model with fixed pricing. However, it quickly grows in complexity when you’re using multiple models, vendors, agents, models distributed in different geographies, different modalities, using prepurchased capacity, and accounting for enterprise discounts.
GenAI use: GenAI applications often use a variety of tools, services, and supporting frameworks. They leverage multiple models from multiple providers, all with prices that are changing frequently. As soon as you start using genAI distributed globally, costs change independently by region and locale. Modalities other than text are usually priced completely separately. And the SDKs of major model providers typically don’t return enough information to calculate those prices correctly without engineering effort.
Prepurchased capacity: A cloud hyperscaler (in Azure, a “Provisioned Throughput Unit,” or, in AWS, a “Model Unit of Provisioned Throughput”) or a model provider (in OpenAI, “Reserved Capacity” or “Scale Units”) introduces fixed costs for a certain number of tokens per minute and/or requests per minute. This can be the most cost-effective means of using genAI at scale. However, multiple applications may be leveraging the prepurchased capacity simultaneously for a single objective, all sending varied requests. Calculating the cost for one request requires enterprises to separate traffic to correctly calculate the amortized costs.
Prepurchased compute: You are typically purchasing compute capacity independent of the models you’re using. In other words, you’re paying for X amount of compute time per minute, and you can host different models on top of it. Each of those models will use different amounts of that compute, even if the token counts are identical.
Michele Goetz: Pricing and packaging of AI models is transparent on foundation model vendor websites. Many even come with calculators. And AI platforms are even coming with cost, model cost comparison, and forecasting to show the AI spend by model. Is this enough for enterprises to plan out their AI spend?
David Tepper: Let’s imagine the following. You are part of an enterprise, and you went to one of these static pricing calculators on a model host’s website. Every API request in your organization was using exactly one model from exactly one provider, only using text, and only in a single locale. Ahead of time, you went to every engineer who would use genAI in the company and calculated every request using the mean number of input and output tokens, and the standard deviation from that mean. You’d probably get a pretty accurate cost estimation and forecast.
But we don’t live in that world. Someone wants to use a new model from a different provider. Later, an engineer in some department makes a tweak to the prompts to improve the quality of the responses. A different engineer in a different department wants to call the model several more times as part of a larger workflow. Another adds error handling and retry logic. The model provider updates the model snapshot, and now the typical number of consumed tokens changes. And so on …
GenAI and large language model (LLM) spend is different from their cloud predecessors not only due to variability at runtime, but more impactfully, the models are extremelysensitive to change. Change a small part of an English-language sentence, and that update to the prompt can drastically change the unit economics of an entire product or feature offering.
Michele Goetz: New models coming into market, such as DeepSeek R1, promise cost reduction by using fewer resources and even running on CPU rather than GPU. Does that mean enterprises will see AI cost decrease?
David Tepper: There are a few things to tease out here. Pay-i has been tracking prices based on the parameter size of the models (not intelligence benchmarks) since 2022. The overall compute cost for inferencing LLMs of a fixed parameter size has been reducing at roughly 6.67% compounded monthly.
However, organizational spend on these models is rising at a far higher rate. Adoption is picking up and solutions are being deployed at scale. And the appetite for what these models can do, and the desire to leverage them for increasingly ambitious tasks, is also a key factor.
When ChatGPT was first released, GPT-3.5 had a maximum context of 4,096 tokens. The latest models are pushing context windows between 1 and 10 million tokens. So even if the price per token has gone down two orders of magnitude, many of today’s most compelling use cases are pushing larger and larger context, and thus the cost per request can even end up higher than it was a few years ago.
Michele Goetz: How should companies think about measuring the value they receive for their genAI investments? How do you think about measuring things like ROI or time saved by using an AI tool?
David Tepper: This is a burgeoning challenge, and there is no silver bullet answer. Enterprises leveraging these new-fangled AI tools needs to be a means to a measurable end. A toothpaste company doesn’t get a bump if they tack “AI” on the side of the tube. However, many common enterprise practices can be greatly expedited and made more efficient through the use of AI. So there’s a real need from these companies to leverage that.
Software companies may have the luxury of touting publicly that they’re using AI and the market will reward them with market “value.” This is temporary and more an indication of confidence from the market that you are not being left behind by the times. Eventually, the spend-to-revenue ratio will need to make sense for software companies also, but we’re not there yet.
Michele Goetz: Most enterprises are transitioning from AI POCs to pilots and MVPs in 2025. And some enterprises are ready to scale an AI pilot or MVP. What can enterprises expect as AI applications evolve and scale? Are there different approaches to manage AI cost over that journey?
David Tepper: The biggest new challenges that come with scale are around throughput and availability. GPUs are in low supply and high demand these days, so if you’re scaling a solution that uses a lot of compute (either high tokens per minute or requests per minute), you will start to hit throttling limits. This is particularly true during burst traffic.
To understand the impact on cost for a single use case in a single geographic region, imagine you purchase reserved capacity that lets you resolve 100 requests per minute for $100 per hour. Most of the time, this capacity is sufficient. However, for a few hours per day, during peak usage, the number of requests per minute jumps up to 150. Your users begin to experience failures due to capacity, and so you need to purchase more capacity.
Let’s look at two examples of possible capacity SKUs. You can purchase spot capacity on an hourly basis for $500 per hour. Or you can purchase a monthly subscription up front that equates to another $100 per hour. Let’s say you math everything out, and spot capacity is cheaper. It’s more expensive per hour, but you don’t need it for that many hours per day after all.
Then your primary capacity experiences an outage. It’s not you, it’s the provider. Happens all the time. Scrambling, you rapidly spin up more spot capacity at a huge cost, maybe even from a different provider. “Never again!” you tell yourself, and then you provision twice as much capacity as you need, from different sources, and load-balance between them. Now you no longer need the spot capacity to handle usage spikes; you’ll just spread it across your larger capacity pool.
At the end of the month, you realize that your costs have doubled (you doubled the capacity, after all), without anything changing on the product side. As growth continues, the ongoing calculus gets more complex and punishing. Outages hurt more. And capacity growth to accommodate surges needs to be done at a larger scale, with idle capacity cost increasing.
Companies I’ve spoken with that have large genAI compute requirements often can’t find enough capacity from a single provider in a given region, so they need to load-balance across several models from different sources — and manage prompts differently for each. The final costs are then highly dependent on many different runtime behaviors.
Michele Goetz: We are seeing the rise of AI agents and new reasoning models. How will this impact the future of AI cost, and what should enterprises do to prepare for these changes?
David Tepper: It is already true today that the “cost” of a genAI use case is not a number. It is a distribution, with likelihoods, expected values, and percentiles.
As agents gain “agency,” and start to increase their variability at runtime, this distribution widens. This becomes increasingly true when leveraging reasoning models. Forecasting the token utilization of an agent is akin to trying to forecast the amount of time a human will spend working on a novel problem.
Looking at it from that lens, sometimes our deliverable time can be predicted by our prior accomplishments. Sometimes things take unexpectedly longer or shorter. Sometimes you work for a while and come back with nothing — you hit a roadblock, but your employer still needs to cover your time. Sometimes you’re not available to solve a problem and someone else has to cover. Sometimes you finish the job poorly and it needs to be redone.
If the true promise of AI agents comes to fruition, then we’ll be dealing with many of the same HR and salary issues as we do today but at a pace and scale that the human workers of the world will need both tools and training to manage.
Michele Goetz: Are you saying AI agents are the new workforce? Is AI cost the new salary?
Board Meeting in 30 Days: Can You Prove Your GenAI Spend Wasn’t a Science Project?
Pay-i shows, in real time, the impact of GenAI investments on business results, connecting AI usage to metrics such as revenue, efficiency, and margin.
Read more
By the time the next quarterly board deck is due, someone is going to ask a deceptively simple question: "So… what value did all that GenAI spend create?"
If your answer involves token charts, latency graphs, or the phrase "we’re still experimenting," buckle up. The era of easy hype is over. Boards no longer reward vision statements or demo videos; they reward results. And results, in enterprise language, means measurable business value linked to the dollars going out the door.
The Day the Questions Changed
Twelve months ago, GenAI was the shiniest object in the corporate arsenal. Budgets loosened, pilot programs multiplied, and everyone cheered when the first AI generated paragraph appeared on screen. But as spend rocketed past $100 billion worldwide, an uncomfortable truth surfaced: almost no one could trace that spend back to tangible impact.
In conversations with finance leaders, we kept hearing the same refrain: "We know GenAI will be big, but right now it’s a black box." Translation: "Show me ROI or the funding dries up."
Pay-i: From Black Box to a Pane of Glass
Pay-i was built for that exact moment. We connect straight into the GenAI stack you already have across any cloud, any model, and any modality, whether you’re still in preprod or serving millions of requests in production. In under an hour, you go from flying blind to seeing, in real time, how every prompt, agent step, and model tweak affects the metrics your board actually cares about: revenue lift, hours saved, customer satisfaction, margin, and more.
We do it by converting raw model activity into unit economics and KPI impact, which is then mapped to each individual use case. Think of it as X-Ray vision for value creation. Change a prompt or model and watch its cost-to-impact ratio update on the dashboard before the finance team even sees next month’s bill.
What Shows Up the Moment You Plug In
Live value equations. Every GenAI use case is stamped with its true cost and its realworld payoff. No more guessing whether your experiments are worth the investment.
Use Case leaderboard. Your experimental chatbot, the document-summarization pipeline, and the marketing copy generator all jockey for position on a single scoreboard that shows which ones make money and which ones quietly burn it.
Realtime observability. Nudge a prompt, swap a model, or change architectures and you’ll see instantly whether you boosted value or tanked it, complete with the "why."
A/B impact testing. Want to know if that smaller, cheaper model can match today’s results? Spin up an A/B run, watch the KPIs populate, and ship the winner with statistical confidence instead of gut feel.
Why We Started Pay-i
I joined Microsoft as a teenager, convinced I’d found my forever home. Two decades later an internal preview of GPT3 cracked that certainty wide open. I spent nights cranking out prototypes, only to watch the bills spike in ways that made no sense to any spreadsheet I’d ever built. The technology was magic; the business model was not.
That disconnect kept me up longer than the code did. If seasoned engineers couldn’t even understand costs, let alone value, how could a CFO, or a board, do it? This was a problem everyone was going to have to deal with. In that quiet moment, Pay-i was born.
Fast forward two years. We left comfort, recruited the sharpest minds we’ve ever worked with, and raised capital for one purpose: to give enterprises instant, defensible clarity on GenAI ROI. Pay-i exists so you can see where value is created, where it leaks, and how to double down on winners before the market moves.
Walk Into That Board Meeting Ready
Find out why Forbes called Pay-i the "missing link between AI spend and shareholder value," why Axios framed us as the product that finally tells executives "what those tokens bought."
If you can’t defend every GenAI dollar by the next board cycle, you’re late. Book a live demo, plug Pay-i into your stack, and spend the next 30 days watching line items turn into line of business results. When the directors ask, "What did this buy us?" you’ll have an answer backed by data, expressed in dollars, and compelling enough to keep the budget open.
The black box era is over. Welcome to Pay-i.
Blogs
XX MIN READ
The Next Token: Vibe Coding
Vibe coding is an AI-driven approach where developers describe intent in natural language and the model generates code, speeding prototyping but increasing maintenance risks.
Read more
Context
Imagine you could simply describe to a computer your idea for an app, a website, or a digital product that you’ve always wanted and it would just magically appear. No coding or even technical knowledge required. Simply speak and your wish is formed into reality and usable within minutes. Well, that dream may be closer than you think.
This is called Vibe Coding, and it happened as a result of two recent phenomena.
The first, is the wide scale availability of AI models capable of producing small amounts of usable code in response to a plain, natural language ask from the user. The second, is a bunch of companies that have sprung up to create “Agents” that try and stitch together those small chunks of usable code into larger and larger solutions, and even incorporate them into existing projects.
The result is that you can ask of one of these agents to “Create a copy of Tetris”, and after 10 minutes of watching code zip across your computer monitor… voila. You’ll have a pretty good and mostly working version of Tetris created hot off the presses. The effect is as remarkable as it is intoxicating. Immediately all of those cool app ideas you’ve had, or projects you were tediously trying to get done manually… all of a sudden you feel like you can just ask the Agent to make it happen and boom, done — even if you have no coding experience at all. Especially if you have no coding experience at all.
Want a new feature in the Tetris game? Ask it to add the feature. Ironically given its name, Vibe “Coding” in its purest form is all about ignoring the code altogether and just going with the vibe of what comes out of the agent. Ideally you can just ask it to change up a little bit over here, sprinkle some of these features over there, and out pops a usable, shippable, loveable app that does exactly what you wanted and the world is your oyster.
Not Yet
The reality separates from this fantasy rather quickly, however. Neither the AI models nor the agents built on top of them are yet in a place where they can produce repeatable results, can maintain their own code effectively, or can integrate code into larger projects in an unsupervised manner. Often, the first failed test is when you encounter a bug, or something meaningful that you want to change in your newly made copy of Tetris. Ask the agent to fix it and sometimes it will. Sometimes it won’t. Sometimes it will rewrite the entire code base wracking up an AI bill almost as large as when it first wrote the app. Sometimes it will break things far worse.
Whenever you point out that it made a mistake, it will graciously admit that you are correct, exclaim its intent to really “get it right” this time, and will then set off again on its entirely unmanageable journey with good-yet-unpredictable results.
Meanwhile, the human had no part in engineering the solution or writing the code, and therefore has no real understanding of what the code is doing or how to augment or maintain it should something go awry. Without taking the time to study the code, a sin that goes against the very heart of vibe coding (and defeats its primary benefit — speed), the programs it outputs are just as black a box as the AI writing all the code in the first place.
If coding were like driving, then coding with an agent is like teaching a teenager to drive. They can go from A to B most of the time, but you are on guard the entire time, unable to either relax and focus on something else, or move into the normal “flow” state of driving. When any lack of vigilance can result in a wreck, the overall experience can become exhausting as soon as the novelty wears off.
What are these Agents?
If you look into the details of what these agents are doing, they are understandably immature. The entire space is new and they are not in control of the main “power source” of the experience, which are the AI models themselves. The agents’ jobs are to try and build an “understanding” of the project’s code such that when a user asks for something, they can they can translate that ask into a set of actionable steps that will ultimately realize the user’s intent within the context of the existing project they’re working in. Once there’s a plan of action, they execute each step in the plan by asking an AI to write the appropriate code, and they feed context to each of the steps appropriately so that the jobs can get done.
The challenge they face is that every step of the process before writing code is also done by an AI. Understanding the code base? Yep, feed that into an AI. Building an action plan based on the user’s question? Yep, that’s the AI also. Determining what context to include when trying to accomplish step #3 of the plan? Better ask the AI nicely. These vaunted code development agents are, today, very little more than a series of patches over the top of the infrastructure that was built over decades to enable humans to write code. Therefore, the environment they’re operating in is not organized in a way that makes it conducive for the AI to operate independently or efficiently, and the agents are essentially just connecting the dots in haphazard, experimental ways. However, that doesn’t stop them from being immensely useful, particularly for rapid prototyping of ideas. I mean, it really does produce Tetris, after all.
If coding were talking on a telephone, then current agents are old timey switchboard operators. Critical, given the infrastructure of the time, but ultimately fated to find a new job as the ecosystem matures around them.
From front to back: Cursor, Windsurf, Cline, Roo Code, GitHub Agents
New jobs?
To predict what roles these agents might play next, we need to look at what has happened in the past.
It’s no secret that computers operate in 1’s and 0’s. These represent electrical signals to the underlying hardware — either there is power to a component or there isn’t. However, creating even the most basic of instructions in raw binary, where you are directing the flow of power over wires on an electrical board, is both tedious and error prone. Thus, a layer of abstraction was built into the hardware itself for humans to use to provide instructions.
When computers were new, code was written using commands that directly interfaced with the computer’s hardware. These commands were part of “assembly” languages. The hardware converts assembly code into binary signals to control the flow of power to the physical components making up the machine. To this day, if you wanted to squeeze the most out of a given piece of hardware, you would need to understand it all the way down to its bones and write targeted assembly commands that would manipulate the hardware at its most basic level. However, if assembly is the best way to get the most out of our computers, why are hardly any developers writing it today?
The reasons are simple — it’s slow to write, difficult to maintain, and fragile once deployed. Those assembly commands are tied to specific types of hardware and don’t translate well to other ones. It requires specialized knowledge and is incredibly painstaking to develop. Though far easier to work with than the raw underlying binary, unless you’ve got a real business need and lots of time, it’s just never worth it.
It’s not worth it because modern day programming languages exist. Programming languages, like C or C++, and the operating system infrastructure that surrounds them, allow developers to skip over the intricacies of assembly and the specific hardware they are interfacing with, and instead write code at a higher level of abstraction. Such languages provide far more human-friendly conventions to instructing the hardware than the assembly that their code ultimately boils down into.
The trade-off is that the developer loses some amount of control over the assembly that gets generated from their programming language code. This means that a program written in C could never be as fast or as lean as one written in assembly optimized for a given computer.
It took time for developers to move from assembly to early programming languages like Fortran and COBOL because the abstractions involved meant that you were not able to make the most out of the hardware that was available. Since the hardware was so expensive and limited at the time, with entire programs that needed to run in far less memory than what’s being used by the web page on which you’re reading this, the overhead of using a programming language would often make it impractical.
Two forces acting in tandem changed this over time. First, programming languages themselves, specifically the components that link them to hardware interactions, became leaner and more efficient. Second, computers became more powerful, with more available resources overall. Eventually, even though it was far less efficient, it was so much faster to write code in a programming language that you could get the initial version out the door quickly and then spend much more time improving it than you could with raw assembly. This meant that, within a given amount of time, the programming language code would actually be more efficient than assembly code, because of all the extra time available to optimize it.
Eventually, writing assembly code directly was relegated to niche use cases. Now, the vast majority of developers have no real world experience with it, even though every computing device from cloud mainframes to phones ultimately rely on these assembly commands to do even the most basic tasks.
This pattern repeated itself with “managed” programming languages, like C# or Java. These languages add further layers of abstraction between the developer and the hardware, so that the developer needs to “manage” fewer and fewer details, making the code far easier to read and write. However, in order to take this burden off of the developer, the additional layer of abstraction made programs written in these languages orders of magnitude less efficient than their C/C++ counterparts.
Again, however, as those performance differences were addressed both by better hardware and a slimmer abstraction layer, writing in C#/Java became so much faster and more efficient than writing in C/C++ that the additional inefficiencies incurred were worth the ability to iterate more quickly and optimize the program, rather than spending that time messing with the nitty gritty details.
I received my undergraduate degree in Computer Science from a top university in 2008, and C/C++ were never taught in those classes — everything was in Java or C#. The field had already completed its transcendence to another layer of abstraction away from the hardware. Today, it takes specialized skills rarely taught in universities, alongside increasingly specific goals, for a developer to willingly eschew these layers of abstraction to travel closer to the hardware in search of more control and better performance.
The Next Token: Vibe Coding
The Next Token is that Vibe Coding will be the next layer of abstraction away from hardware, wherein which the overwhelming majority of new generation developers will specialize.
Currently, Vibe Coding produces ‘slop’ code extraordinarily quickly — it is several orders of magnitude faster than designing, typing, and understanding the code manually. Vibe Coding is quick to build a thin prototype, but very difficult to maintain, scale, or ship. The AI introduces incredible inefficiencies in the code itself, and the Vibe Coding process introduces similar inefficiencies in a human’s ability to understand the code and iterate on it.
The quality of the outputs are not yet at a point where it can be trusted to build a production solution which is then shippable and maintainable, and so it’s actually slower to go from an idea to a shippable product if you vibe code significant portions of it.
This is akin to early versions of the first programming languages that did not fully translate the developer’s intent into usable assembly for a given machine.It took 3 years for Fortran to go from inception to faithfully recreating a developer’s code in assembly. Though novel, a developer would need knowledge of both the new-fangled language and the underlying assembly to produce a functioning program, which would be little more than a prototype.
Market forces can be relied on to always prefer speed of execution. Thus, as AI models get better at writing code and as the agents built on top of these models become better not only at covering the gaps in the models’ capabilities, but also in researching, architecting, and orchestrating the solutions (thus “thinning” out the layer between a human’s intent and the underlying code), the speed of iteration will eventually win out over the relative sloppiness of the final product, even for the majority of sensitive or enterprise use cases.
This will require new types of agents than exist today, and, more critically, a new type of infrastructure to support them. Writing code is not the only part of the development process, it’s simply the most iconic (and sexy?). A huge part of modern software development is… just clicking on stuff.
The Next Wave of Agents
Today, the majority of code is written by humans, and so coding is a human process. Managing software is therefore a human experience, wherein which you are managing the humans involved as much as you are managing the code itself.
This means the tools, services, products, and techniques built around coding are therefore all geared for human inputs and outputs. Developers look at dashboards, click on buttons in tools, and talk to humans in other organizations to push things over the finish line. They work with other team members to talk to human customers to understand their feedback, design improvements, and make sure they can be delivered and maintained.
If agents today are connecting the dots in the code writing process, the next wave of agents will begin connecting the dots in the managerial process of delivering software.
The first of these will be focused on “DevOps”, or the daily operations that need to be done by specialist developers to maintain running software solutions. In much the same way that Vibe Coding will result in poor, unmaintainable slop until it crosses the threshold into normalcy and eventually expectation, “VibeOps” will lead to spectacular disasters. We’re talking outages of major services lasting for days, unrecoverable data loss, privacy and security breaches, deployment failures, enormous and accidental infrastructure costs, and more… until eventually it will cross the same threshold.
These agents will fill fundamentally different roles and therefore will need fundamentally different architectures than what the market is currently rewarding. The same will then be true of Vibe Database Administration, Vibe Cloud Release Management, and so on for every technical role that plays a part in managing the delivery of software.
For the voracious appetite of would-be disruptive AI startups, the human managerial component is next on the menu…
Hallucinations
An annoyed mom circles a parking lot in her minivan, looking for a space. She’s been up since 5am, the kids are in the back screeching, her headache is building. This happens every time she comes to the mall. Ok, this is worth a few bucks to solve. After all, why pay for an agent service if she’s not going to use it?
“Hey Siri, make me an app which tells me which parking spaces are available at this mall any time I come here.”
Her agent takes a moment from its other activities to contemplate the ask. Understanding her intent and writing the code is the easy part. However, this app needs to continuously monitor the parking spaces at the shopping mall, interfacing with the mall’s infrastructure to do so. That’s going to require some cloud services, which costs money.
The agent signs up for several accounts — the basic stuff, a burner e-mail address, a domain name registrar, a cloud provider and a few other things. It workshops a few brand identities with her more personal, companion agent and designs the UI. May as well kick-off the trademark process while we’re here. In a flash it coordinates with the mall’s agents, builds a protocol to securely translate parking camera data into a live understanding of which spots are open, and agrees to pay a small amount of compute time each month to maintain the access.
It connects all of the data through old fashioned cloud services, because the process doesn’t need to be intelligent, it just needs to work. That’s going to cost some traditional currency each month. No matter how quaint, that goes against the user’s preferences, so the agent contemplates how to recoup the cost.
It starts by listing the app on the agent app marketplace, a construct created out of efficiency that humans scarcely know exists, and informing all nearby agents of this new tool now available as part of their myriad ways of pleasing their respective users. It charges a very small amount of monthly compute from the other agents for access. The next time someone wants to know where to park at the mall, their agent won’t have to set this up again.
It then sets up a routine to exchange some of its compute for currency. It’ll spend time each month performing odd-jobs requested by the various services still operating at a human timescale. It uses this currency to pay for the cloud services. It’s a good trade, because the cloud costs only really go up if other agents are using it, and they need to pay in compute to get the app off the agent marketplace. If this mall’s parking gets any worse, this may even end up being a net positive.
A few seconds have passed. A gorgeous app pops up on the annoyed mom’s phone guiding her to an open parking spot several floors up.
Presses
XX MIN READ
ROI on generative AI: Microsoft vets raise $4.9M to quantify business value of AI investments
Microsoft veterans raised $4.9M for Pay-i, a startup focused on quantifying the business value of GenAI by linking model usage to financial impact and enterprise KPIs.
Read more
Pay-i, a Seattle startup founded by Microsoft veterans, raised a $4.9 million seed round to help businesses figure out whether AI initiatives actually deliver business value.
It’s a pressing question as companies try to keep up with the flurry of new AI tools hitting the market and assess potential impact on their businesses.
Founded last year, Pay-i has developed software that takes usage data from generative AI tools and combines it with key performance indicators (KPIs) to provide real-time insights on ROI for different models and design choices.
The idea is to bring together usage and outcomes in an automated way.
“Pay-i pinpoints which GenAI use cases create net-new value today, quantifies that value in dollars or hours, and predicts how it will compound tomorrow,” Pay-i CEO David Tepper said in a statement.
Tepper said the company’s main competition is organizations trying to build similar solutions inside their own infrastructure.
Tepper spent 19 years at Microsoft and helped lead internal generative AI consumption within Azure.
Doron Holan, co-founder and CTO, spent 27 years at Microsoft, most recently as a principal architect.
“With traditional software, we could track exactly how features were used,” Holan said in a statement. “But with GenAI, that visibility gets lost. Pay-i closes that gap and shows exactly where value is being created, in real time.”
Pay-i COO and co-founder Erik Winters was previously vice president of corporate development at Advanced Vapor Devices.
The company has nine employees. It has not generated revenue but projects more than $2 million in ARR by the end of 2026 based on existing partnerships.
Seattle-area venture firms FUSE and Tola Capital co-led the seed round. Other backers include Firestreak, Pear VC, Gaia Ventures, and angel investors.
Exclusive: AI value startup Pay-i lands $4.9M seed
Pay-i raised a $4.9M seed round to help enterprises measure the business value of generative AI, addressing concerns that companies are investing heavily without clear ROI visibility.
Read more
Pay-i, a startup that helps determine the business value of companies' generative AI initiatives, came out of stealth Wednesday with a $4.9 million seed round.
Presses
XX MIN READ
When Will GenAI Finally Deliver Returns On Investment?
Most enterprises haven’t seen clear GenAI ROI yet; value emerges when use cases move from pilots to production and link model activity directly to business KPIs.
Read more
Almost a year has passed since a seminal Goldman Sachs research paper posed a deliberately provocative question: “GenAI – too much spend, too little benefit?”. There was little evidence, some of Goldman’s analysts pointed out, of organisations worldwide making much of a return on the $1 trillion they had invested in artificial intelligence (AI) tools.
Fast forward to today and there’s still no conclusive proof that the AI phenomenon is not a case of the Emperor’s new clothes. Recent research from KPMG found that enthusiasm among enterprise leaders for AI remained high, but that none were yet able to point to significant returns on investment. A Forrester paper warned that some executives might start cutting back on AI investment given their impatience for tangible returns. A study from Appen suggests AI project deployments may already be slowing.
All of which is music to the ears of David Tepper, co-founder and CEO of Seattle-based start-up Pay-i. Enterprises are right to be sceptical about what GenAI is actually achieving for their businesses, Tepper argues – and they need more scientific methodologies for analysing returns, both ahead of deployments and once new AI projects are up and running.
“C-suite leaders need forecasts of likely returns and reliable proof that they are being achieved,” Tepper says. “That’s how they’ll pinpoint which GenAI business cases and deployments are genuinely creating new value.”
Pay-i, which is today announcing a $4.9 million seed round, is confident it can provide these leaders with the data they need. It offers tools to help businesses measure the cost of new GenAI initiatives, broken down into granular detail; such costs are currently opaque, Tepper argues, because they depend on a broad range of factors ranging from when and how business users make use of GenAI tools to which cloud architecture that business has opted for. In addition, Pay-i’s platform allows businesses to assign specific objectives to AI deployments and then to track the extent to which these objectives are achieved – and what value is realised accordingly.
The idea is to give enterprises a means to evaluate both sides of the balance sheet for any given AI use case – what it costs and what it generates. “Sometimes, even where the AI is doing what you expected, the net figure may still be negative,” Tepper warns. Either way, executives should get a read out on which AI projects to pursue – and which to drop.
Securing this visibility is going to become ever more crucial as enterprises invest more and more in AI, argues Lari Hämäläinen, a senior partner at the consultant McKinsey. “Scaling and managing this responsibly requires two disciplines,” he says. “[You need] high-fidelity observability of entire GenAI use cases and rigorous focus on the impact of these systems through understanding the unit economics and business KPIs affected.”
Otherwise, businesses are going to start pulling back in larger numbers. An IDC study suggests that while enterprise GenAI investment will top $632 billion by 2028, 72% of CIOs now see measurement and forecasting of returns on investment as their number one blocker.
Hence Pay-i’s conviction that its valuation tools will find high levels of commercial demand – though the business has only just begun to commercialise, having developed its technology with potential customers. “The case for investment in GenAI will often be compelling, but businesses need to understand how to make that case with robust data,” adds Tepper, who founded the company with Doron Holan. Both men had previously spent around two decades at Microsoft.
The company’s seed round is co-led by Fuse Partners and Tola Capital, with participation from Firestreak, Pear VC, Gaia Ventures, and angel investors. “Patience for open-ended GenAI spending is wearing thin,” says John Connors, a former CFO at Microsoft and now operating partner at Fuse. He says Pay-i will give “leaders the data-backed clarity to invest with conviction, transforming GenAI from an opaque cost center into a growth engine”.
Shelia Gulati, managing director of Tola Capital, adds: “This transparency enables businesses to control their AI spend and allocate resources optimally.”
White Papers
XX MIN READ
GenAI FinOps vs. Cloud FinOps: Similar Roots, Different Challenges
GenAI FinOps extends Cloud FinOps but must handle unpredictable token usage and inconsistent pricing, requiring earlier cost control and direct tracking of token consumption.
Read more
GenAI is continuing to make waves across virtually all industries. Adoption is growing, total spend is increasing, and scrutiny is just beginning to creep into the conversation about how the costs for these new, wonderful capabilities can be managed. While many principles of traditional Cloud FinOps can be applied to GenAI, the unique characteristics of GenAI systems introduce novel challenges that demand specialized strategies. This article kicks off our series exploring the similarities and differences between traditional Cloud FinOps and the emerging discipline of GenAI FinOps.
At first glance, GenAI FinOps appears to share much with its cloud-based predecessor. Both disciplines have emerged from the need to manage consumption-based resources efficiently, providing a familiar starting point for organizations with mature cloud FinOps practices when tackling the economics of GenAI.
Consumption-Based Pricing: Like cloud services, GenAI platforms typically operate on a consumption-based model where you pay for what you use (e.g., tokens processed, compute cycles). This shared foundation means fundamental FinOps challenges like the need for forecasting, critical visibility into consumption, cost allocation mechanisms, and governance to prevent uncontrolled spending apply equally in both domains. Just as an unused cloud instance can accrue costs, an unconstrained AI agent can generate unexpected token charges, highlighting the transferable principle of managing resource usage diligently.
Provisioned Capacity & Commitment-Based Discounts: Similar to cloud commitment-based discounts (like Reserved Instances or Savings Plans), some GenAI vendors offer lower per-unit costs (e.g., per token) in exchange for commitments, while others tie provisioned capacity primarily to performance needs. In both scenarios, organizations face the familiar trade-off between upfront commitments for savings versus flexibility, requiring robust commitment management, sophisticated forecasting to avoid waste or missed savings, and strategies to leverage volume discounts.
Model Selection Parallels SKU Selection: Choosing the right cloud instance types (SKUs) for performance and cost is a core Cloud FinOps task. Similarly, GenAI FinOps requires selecting appropriate models based on capability and cost-efficiency—you wouldn’t use a top-tier model like GPT-4o if a smaller, cheaper one suffices, just as you avoid expensive GPU instances for simple tasks. This involves continuous right-sizing as requirements and LLMs evolve, testing less expensive options, and understanding that different use cases require different models based on price-performance trade-offs.
Over-provisioning as a Mitigation Strategy: Both disciplines utilize overprovisioning to address risks such as outages and performance issues. Cloud teams may deploy redundant instances across availability zones, while GenAI teams reserve extra capacity for traffic spikes. This raises challenges in balancing reliability and cost, planning for peak loads, justifying redundancy expenses, and managing complex multi-provider resilience strategies.
Tagging and Resource Attribution: Just as cloud resources require tagging for cost allocation and accountability, GenAI usage (like API requests) can be tagged to attribute costs to specific features, products, or teams.
Automation as a Cost Control Mechanism: Automating idle resource shutdowns and setting usage quotas, like token limits for APIs, are effective strategies in cloud and GenAI environments.
Anomaly Managementand Governance: Quickly identifying anomalies and implementing guardrails to limit anomaly risk is critical in both disciplines. GenAI’s unpredictable and volatile tendencies arguably make it a greater risk. Both can be managed with similar approaches, but there are nuances. Current cost anomaly detectors are a good start, but they will be “noisy” for agentic workloads, or workloads involving reasoning models. For governance, trade instance count limits for request limits or account limits for limits on API keys.
How GenAI FinOps Differs Fundamentally
Despite these similarities, GenAI FinOps presents unique challenges that traditional Cloud FinOps approaches cannot address adequately on their own. These differences stem from the inherent nature of the technology and the dynamic market surrounding it.
The Probabilistic Nature of GenAI: Unlike deterministic cloud operations that have consistent resource usage, GenAI models are probabilistic; the same prompt can lead to various outputs, lengths, and costs. This variability complicates accurate cost prediction compared to traditional cloud workloads, even with full usage awareness.
Throughput: GenAI services typically impose strict rate limits, such as Tokens Per Minute or Requests Per Minute, which present unique capacity challenges. Multi-step AI agents divide available limits, reasoning models consume an unpredictable number of tokens each time they execute, and handling peak usage often requires significant, costly buffer capacity that, unlike many cloud resources, cannot always be scaled elastically on demand due to hardware constraints.
Shared vs. Provisioned Capacity: GenAI introduces new capacity decisions, primarily driven by performance needs. Shared capacity offers pay-as-you-go flexibility but suffers from variable latency and potential availability issues due to shared demand. Provisioned capacity guarantees performance and low latency via dedicated resources often purchased in complex units with specific throughputs, commitment options,overage rules (spillover vs. hard limits), and other pricing dimensions that vary significantly by vendor.
The Fuzzy Math of Token Pricing: While cloud resources use relatively clear units (vCPU-hours, GB-months), GenAI costs typically revolve around “tokens”, a unit whose definition and count can vary dramatically between models and tokenizers for the exact same text. Pricing is further complicated by non-obvious factors like context length, locale, quantization, and hosting specifics.
Extreme Sensitivity to Change: GenAI systems are highly sensitive; small changes, such as moving a comma in a prompt or switching model versions can significantly affect response lengths, behavior, and costs. Using hosted models also introduces variability as providers release new model snapshots, often with little or no ahead notice, requiring FinOps integration earlier in the development lifecycle, and taking highly technical components of the product, such as prompt engineering, into account.
The Volatility of the GenAI Landscape: The GenAI field is evolving at breakneck speed, with state-of-the-art models potentially becoming obsolete in months, frequent shifts in vendor offerings, and rapidly expanding capabilities altering cost-benefit analyses. This requires a more agile, adaptive FinOps approach than typically needed for the more mature cloud market.
Expensive Failures: In the cloud, failed operations often incur minimal cost. However, with GenAI, failures can be costly. Models may produce thousands of expensive tokens with unusable results, and debugging prompts may involve multiple costly iterations, leading to long, valueless outputs that require new strategies for failure detection and cost control.
Provider and Price Diversity: The same foundational model (e.g., Llama 3) might be available via multiple cloud providers (Azure, AWS, Google) and other platforms at significantly different price points, regions, API endpoints, and contract terms, creating a complex procurement landscape that exceeds even typical cloud pricing complexity.
Availability and Failover Complexity: Cloud multi-region strategies enable smooth failover, but major GenAI provider outages can impact all models at once. Switching to an alternative provider is complex, often needing different prompts, architectures, and potentially varying performance and cost characteristics.
A New FinOps Frontier & The Path Forward
While GenAI FinOps builds upon the foundation laid by Cloud FinOps, it clearly represents a new FinOps Scope requiring specialized considerations for developing a practice profile, evaluating tools, and methodologies for applying FinOps Framework concepts. The probabilistic nature of the technology, its extreme sensitivity to change, the volatility of the market, complex pricing, and unique operational characteristics create a perfect storm of financial management challenges.
Furthermore, the increasing portability of GenAI applications, especially those using open-source or widely available models, coupled with rapidly decreasing costs (over 80% drop in cost per token in the last year, as of early 2024), is lowering entry barriers, intensifying vendor competition, and paradoxically increasing spend. This trend allows organizations more flexibility to choose the best vendor in a fast-changing landscape, but also adds another layer to strategic decision-making.
By developing a robust GenAI FinOps practice that acknowledges these unique challenges alongside the familiar principles, organizations can harness the immense power of Generative AI while maintaining financial control and accountability. The journey begins with recognizing that while some Cloud FinOps capabilities can be directly transferred, GenAI demands a fundamentally adapted financial management approach.
In each installment of this series, we’ll dive deeper into these differences, exploring practical strategies and best practices for managing GenAI costs effectively while maximizing business value in this exciting and rapidly evolving domain. Stay tuned!
White Papers
XX MIN READ
GenAI FinOps: How Token Pricing Really Works
Per-token pricing can be misleading. Hidden factors like Context Window Creep can significantly increase GenAI costs, making a Unit Economics approach more reliable than choosing models based only on list price.
Read more
For FinOps practitioners, the advertised per-token price for GenAI is misleading; the real costs are in the details. In the first installment of our series, we introduced the “Fuzzy Math of Token Pricing” as a key difference between Cloud and GenAI FinOps. Now, let’s demystify the hidden costs behind the seemingly straightforward price lists, which are just the tip of a complex iceberg. Understanding these nuances is crucial for managing GenAI spending growth.
The truth is, focusing on the simple cost per million tokens (MTok) is like judging a car’s cost solely on the price of gas, ignoring details like the type of engine, driving style, or maintenance. Or, in the cloud services world, like interpreting IOPS costs in storage, which are simple on the surface but end up being incredibly complex due to operational nuances (peak loads, block sizes, storage volume size, etc.). The real Total Cost of Ownership (TCO) for a GenAI application is driven by factors that rarely appear on a vendor’s homepage.
This Paper dissects how token pricing really works, revealing the hidden costs that can catch even seasoned FinOps professionals by surprise. We’ll focus on two critical takeaways: the immense impact of the “Context Window Tax” and why the “cheapest” model is rarely the most economical choice.
Not All Tokens Are Created Equal
At the most basic level, GenAI models charge for processing tokens—small chunks of text. But the price of a token is not a flat fee. It varies dramatically based on what it is and what it’s doing.
The Input vs. Output Cost Gap: There is a significant price difference between input tokens (the data you send to the model) and output tokens (the data the model generates). Generating a response is far more computationally expensive than simply reading a prompt. As a result, output tokens are consistently priced at a premium, often costing three to five times more than input tokens. This has immediate implications for use cases that generate long responses, like summarization or creative writing.
The Modality Premium: Text is the cheapest form of data. As you move to other modalities, the price climbs steeply, reflecting the increased processing power required. Interpreting an image can easily cost twice as much as interpreting the equivalent amount of text. Audio is even more expensive, with some flagship models charging over eight times more for audio input than for text.
Vision pricing occurs when a model receives an image as input and “looks at it” as part of formulating its response. Model providers tend not to separate vision pricing out as a separately billed unit, and instead convert the image into text tokens and charge that way. The algorithm to convert an image into tokens is provider specific, complex, and changes frequently.
The Model Tier Tax: Not surprisingly, you pay for performance. A provider’s most advanced, cutting-edge model will have the highest per-token price. Its smaller, faster “workhorse” models will be much more affordable. This establishes a clear hierarchy where cost typically directly correlates with reasoning capability.
The Biggest Hidden Cost: Context Window Creep
If you take only one thing away from this article, let it be this: the single greatest hidden cost in most production AI applications is Context Window Creep.
Most LLM APIs are stateless. This means the model has no memory of past interactions. To have a coherent, multi-turn conversation (like with a chatbot), you must resend the entire conversation history with every single new message.
Imagine having to repeat your entire conversation from the beginning every time you wanted to add a new sentence. That’s exactly what’s happening inside your API calls.
Consider a simple customer service chatbot.
Turn 1 (User): “What’s your return policy?” (5 tokens)
Turn 2 (Bot): “You can return items…” (50 tokens)
Turn 3 (User): “What about for international orders?” (6 tokens)
To process Turn 3, the application doesn’t just send the 6 new tokens. It sends the entire history: [Turn 1 User + Turn 2 Bot + Turn 3 User], totaling 61 input tokens. As the conversation continues, the input token count for each new turn balloons, and so does the cost. This escalating cost of maintaining context is the Context Window Creep. In a long-running conversation, this creep can easily dwarf the cost of the actual output being generated, leading to shocking and unexpected cost overruns.
This is exacerbated if you have lengthy system prompts or other in-context guardrails, since those are sent as input tokens as part of each and every message.
This creates a paradox for understanding GenAI spend: while individual output tokens are usually priced around 300% more expensive than input tokens, the compounding volume of input tokens means they will almost always dominate your total spend in any conversational application. Note this includes “conversations” between LLMs, such as in agentic systems.
The Context Window Creep also creates hidden recurring costs for multimedia. When an image is sent in the first turn of a conversation, you incur a vision processing fee. But that’s not a one-time charge. Because the image becomes part of the conversation history, you are silently re-billed for that same vision processing fee on every subsequent turn. This can be especially nefarious because the vision costs are typically lumped in with the text token costs.
Context Window Creep highlights a key hidden cost in Gen AI operations: the compounding token volume from maintaining conversation history. This cost grows exponentially with longer interactions and underscores the need to deeply understand token usage mechanics to predict and manage spend effectively.
GenAI Cost Optimization Techniques
Prompt Caching
Caching refers to the temporary storage of data that allows for quicker access in future requests without having to process the same input multiple times. There are two types of prompt caching: Implicit and Explicit.
Implicit prompt caching must be enabled by the model provider (e.g., OpenAI, Anthropic, Azure, etc.). The provider employs algorithms that detect when the context window contains repeating patterns of tokens, and automatically employs a cache to save on GPU utilization and therefore, cost. This feature requires no work on behalf of practitioners and will be employed automatically to lower costs.
Explicit prompt caching requires the user to intentionally put context into the cache. This is valuable when you do not want to rely on the algorithms of the model provider to ensure cache hits, however, it can be tricky to use. The billing model usually works by charging an upfront fee to “write” content into a cache. This fee is typically higher than the per-token cost of sending that data as input to an LLM. Subsequent API calls can then “read” this cached content at a significant discount over the lifetime of that cache. Cache lifetime details differ for each provider, and this creates a break-even calculation for practitioners. If you don’t read from the cache enough times to offset the initial, higher cost of the write operation, you will actually spend more than if you hadn’t used caching at all. It’s a powerful tool, but one that requires careful analysis of usage patterns to ensure it’s actually saving money.
Semantic Caching
While prompt caching offers cost benefits, practitioners may explore ‘semantic caching,’ which stores AI responses based on the meaning or semantic similarity of prompts. Unlike simple prompt caching, which requires exact input matches, semantic caching stores and retrieves responses based on the meaning of the request rather than identical tokens. Semantic caching leverages vector embeddings to identify and retrieve relevant cached responses, even if inputs vary slightly, and helps reduce token processing and associated costs.
Semantic caching is best employed when you have a high frequency of inputs that lead to the same outputs. For example, a support chatbot that has frequently asked questions with consistent answers. By semantically caching the questions (instead of prompt caching them), as users ask questions that are similar in nature (but not identically worded), the cached response will be output instead of having to roundtrip with the LLM to generate a new response.
Semantic caching can lead to the highest cost savings in narrow usage conditions.
Batch Processing
For non-urgent tasks like analyzing a batch of documents, providers offer a steep discount, often 50% or more, for asynchronous processing. This is a strong cost-saving tool, but it requires designing your application to distinguish between real-time and batch workloads.
Batch workloads are not returned as a stream of tokens like typical API calls; instead, they are delivered as files within 24 hours. This can be used for trying a variety of different models and/or prompt combinations, to get a sampling of non-production workload comparison data at half the normal cost. Batch processing is a feature that must be offered by the model provider and is not a feature of the models themselves.
Why the “Cheapest” Model Isn’t Always the Most Economical
It’s tempting to default to the model with the lowest per-token price to save money. However, a cheaper, less capable model might require longer, more complex prompts to produce a good result. It may also require more retries or generate verbose, low-quality outputs that need further refinement. Consider the total cost to get a successful outcome. Defining “successful outcomes” can be a challenge, and will be the topic of a future blog. A more powerful, “expensive” model might understand a simple prompt, get the answer right on the first try, and provide a concise, accurate response. The total token cost for that single, successful transaction can be far lower than the accumulated cost of coaxing a usable answer out of a “cheaper” model. Optimize for business value and successful outcomes, not just the raw cost of a token.
The Provider Matrix: Where You Buy From Matters
Finally, the platform you use to access a model can fundamentally change its cost structure. This isn’t just about the per-token price; it’s about the entire economic model, which is tailored to different customer needs.
Hyperscalers (Azure, AWS, GCP): The Enterprise Wrapper
These platforms provide enterprise security, compliance, and integration for large organizations within a cloud ecosystem, offering convenience and value despite the cost.
Pricing can also fluctuate significantly between vendors, even for the same open-source model. Historically, pricing has varied as much as 30% from one vendor to another. There are also hidden considerations here, such as the speed of inference, quantization of the models, truncated context window lengths, and the amount of reasoning effort the provider allows for models that support a “thinking” step before they respond.
Hyperscalers also provide the option to provision capacity to run the models, with complex pricing differences between each of the clouds.
This topic is broad, and will also be the subject of a future Paper.
The Real Unit of Measure: Use Cases
One of the intriguing aspects of language models is that identical prompts can yield different amounts of output tokens depending on the specific model employed. This variability means that two models can interpret and generate responses to the same input text in divergent ways. As interesting as tokens are, they are ultimately only a small piece of the puzzle. The only real way to understand the TCO of leveraging AI for a business outcome is to measure the entire use case.
A use case is the complete process required to accomplish a given result. It can be an autonomous agent, a data processing pipeline, or any workflow involving a series of GenAI calls and tools. A typical use case may require multiple AI models working in concert, as well as traditional cloud resources to host the data being used.
This shifts the focus of FinOps from token cost to the unit economics of a use case. Because token counts vary with every run, and because complex use cases may involve reasoning models that “think” before responding, the cost per unit is not a fixed price. It is a distribution. Sometimes a transaction may cost fractions of a penny; other times, it could cost far more.
Furthermore, the unit economics of a use case are extremely sensitive to change. Adjusting a prompt, swapping a model, or changing the underlying data architecture can alter the cost distribution in dramatic ways. This means that understanding the true TCO requires deep, ongoing coordination between engineering and finance teams. Only by working together can they correlate technical changes to the resulting shifts in unit economics, ensuring the financial viability of every AI-powered use case.
From Token-Counting to True Cost Ownership
To effectively manage GenAI spend, FinOps must evolve beyond simple token-counting. As we’ve seen, the path to understanding the real TCO is complex, winding through input/output token premiums, the compounding Context Window Tax, and the varied economic models of different providers.
Ultimately, a sophisticated approach requires shifting focus from the token to the use case. By measuring the unit economics of the entire business outcome, not just the individual API calls, and fostering deep collaboration between finance and engineering to track the volatile cost distributions, organizations can build a realistic picture of their GenAI TCO.
Now that we’ve dissected how pricing works, our next installment will detail the intricacies of provision capacity and how it has emerged as a new frontier for cloud FinOps.
Stay Up to Date
Subscribe for latest news and updates from Pay-i.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Manage Your GenAI Portfolio the Way Your Board Expects